Quick Start
The Parse endpoint converts documents into structured, LLM-ready formats. Use it to extract clean document content for downstream processing such as RAG pipelines, custom ingestion workflows, document extraction tasks, Agents, etc.
This quickstart will get you up and running with the Parse API in under 5 minutes to extract structured content that can be passed into your LLM/Agent as context or further processed.
What we’re going to parse
We’ll use a bank statement to demonstrate the Parse API.

Feel free to use this document to follow along with the quickstart!
Using the Parse API
Choose your preferred language to get started.
If you’re using an SDK, see installation instructions. For raw REST calls, you can use the built-in fetch API (Node.js 18+) or requests in Python.
Replace <YOUR_API_KEY> with your actual key, available on the Developers page, then run one of the examples below to parse the document.
Each example sends a document to the Parse API and returns structured content split into page-level chunks.
Note: this doesn’t set any configuration options, so the parser will use the default settings. For configuration details, see Configuration Options.
For high-volume production workloads, use asynchronous parsing. For more details, see Async vs. sync processing.
Example response (truncated)
After you run the code snippet above, you’ll see a response like this. This example response is truncated for brevity. The response is organized into chunks, which in this case are page-level units. Each chunk includes a formatted content string for the full page and a blocks array for block-level elements (like text, tables, and figures) with metadata and spatial data.
Key fields
For full request/response details, see the Parse File API reference.
Using Parsed Output
You can access the formatted content of each chunk or work with individual blocks for more control.
For a deeper guide on how to use the output of this endpoint, see Response Format.
Using Extend Studio
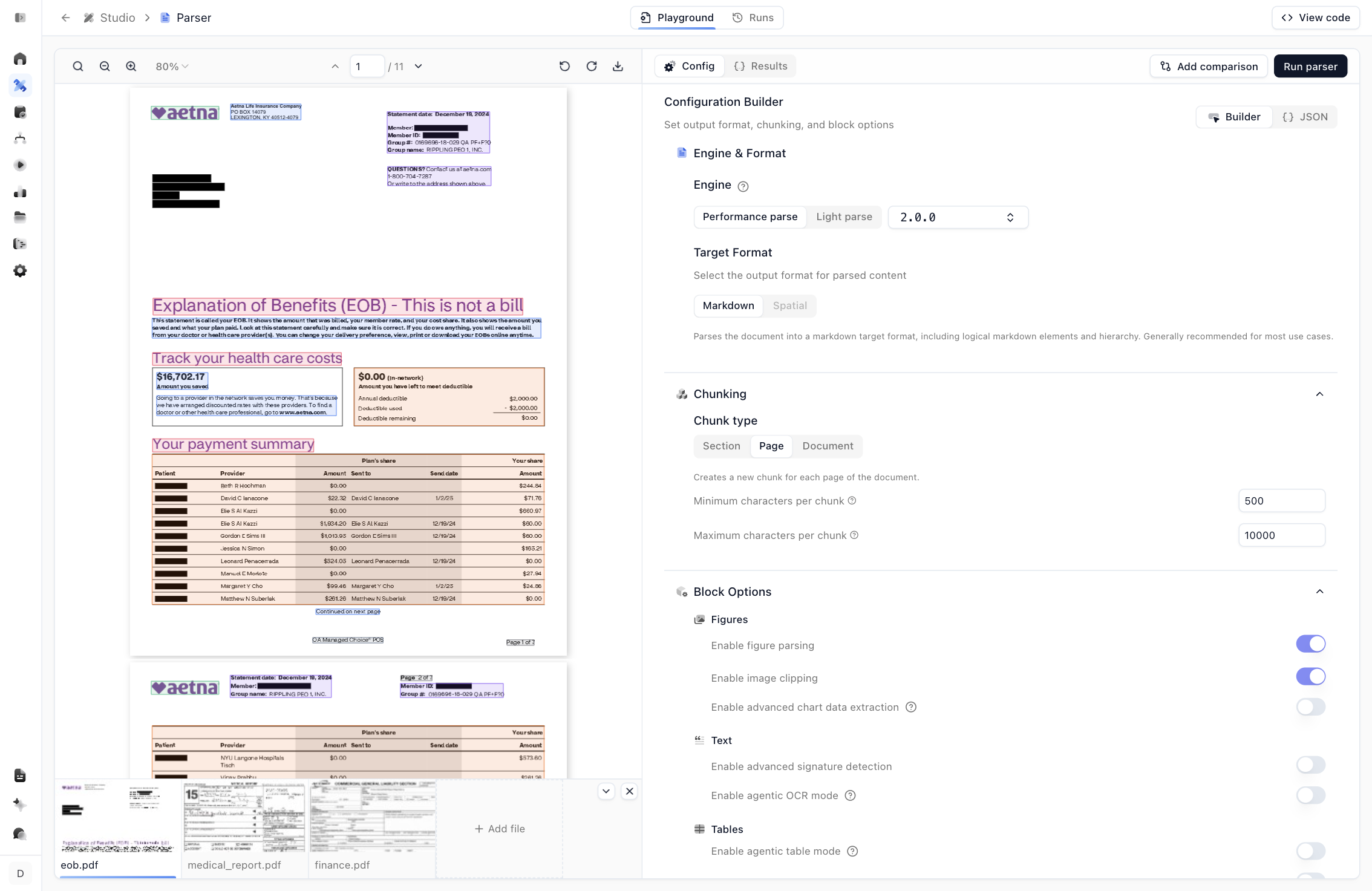
You can also use Extend Studio UI to upload your document, configure the parser, and view the code to copy.
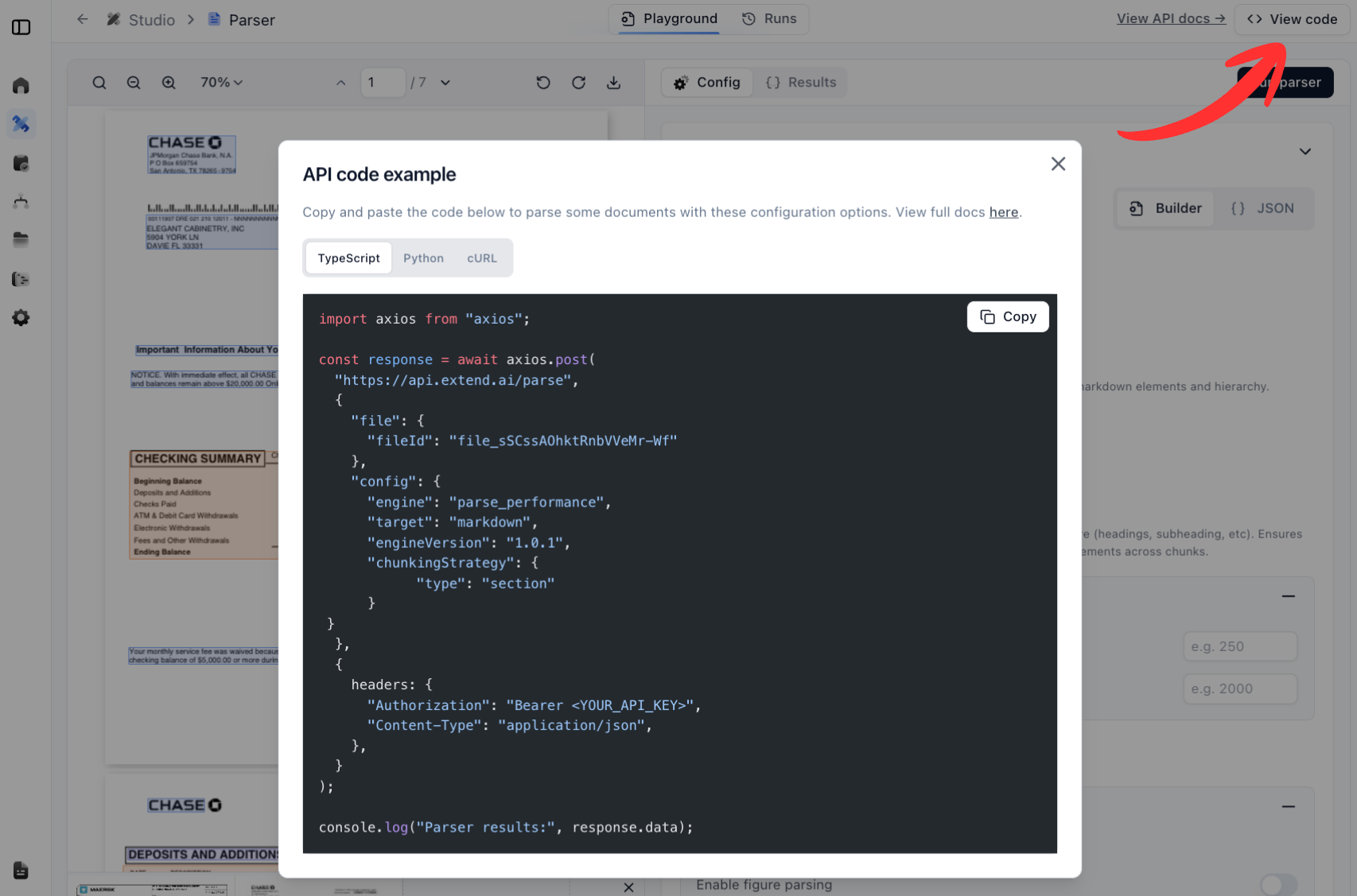
Here, you’re also able to go to the Config tab to edit the parser configuration and copy the JSON config.
Next steps
Customize chunking, output format, and block options
Ready-to-use configs for RAG, legal docs, and more
Extract tables, figures, and spatial data
Optimize for speed or accuracy
Handle errors and troubleshoot issues
Full request and response schema