Edit API, Review Agent, New Extraction Version, Large Array and Citation Strategies, and more

We’re excited to share our latest updates that bring powerful new capabilities for document editing, smarter confidence scoring, and enhanced extraction strategies:
- ✏️ Edit API - Fill any form programmatically with template-based or free-form based approaches
- 🧠 Review Agent - Agentic confidence scoring system that automatically detects and scores extraction issues
- 🆕 New Base Extraction Version - Two new base extraction versions that deploy new models and adds support for new large array extraction/citation strategies
- 🔢 New Array Extraction Strategies - More control over how arrays are extracted and processed
- 📑 Array Citation Strategy - Configure the granularity of citations for extracted arrays between
itemorpropertylevel citations - And more…
Let’s dive in!
Edit API
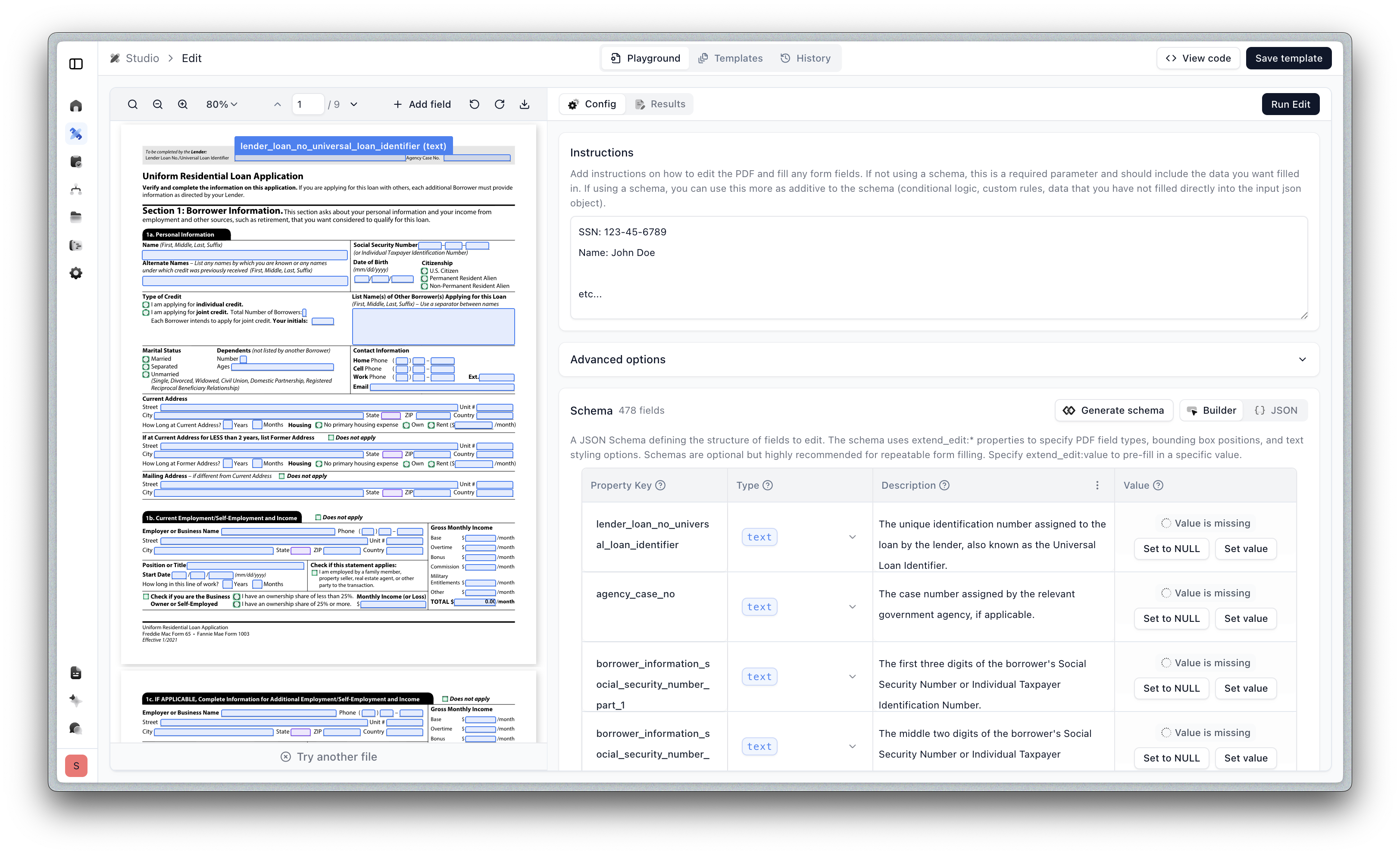
We’re excited to release our new Edit API and Studio experience to fill any form programmatically. It’s ideal for automatically filling out PDF forms, pre-populating documents with customer data, and generating filled documents at scale.
Two approaches for different use cases:
Template-based filling is for forms you know ahead of time: tax documents, disclosure forms, standard contracts, compliance paperwork.
Instruction-based filling is for scenarios where you don’t know the form structure ahead of time and need auto-detection and on every run. Perfect for AI agents that need to complete forms as part of larger workflows, or when handling documents from many different sources where you can’t pre-configure templates for each one.
Under the hood, Edit combines state of the art object/form field detection models with vision-language models to understand document layouts visually. It can identify text fields, checkboxes, radio buttons, tables, and how they relate to labels and surrounding content.
View documentation here.
Review Agent
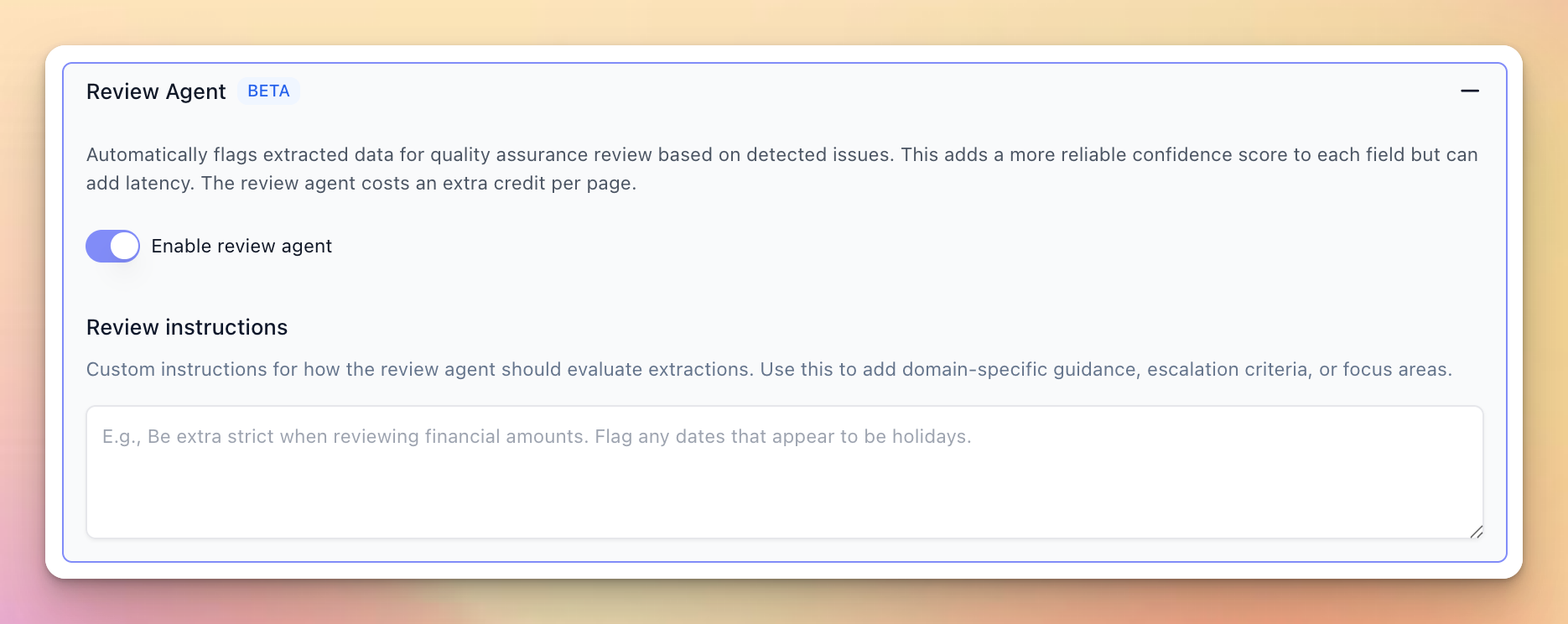
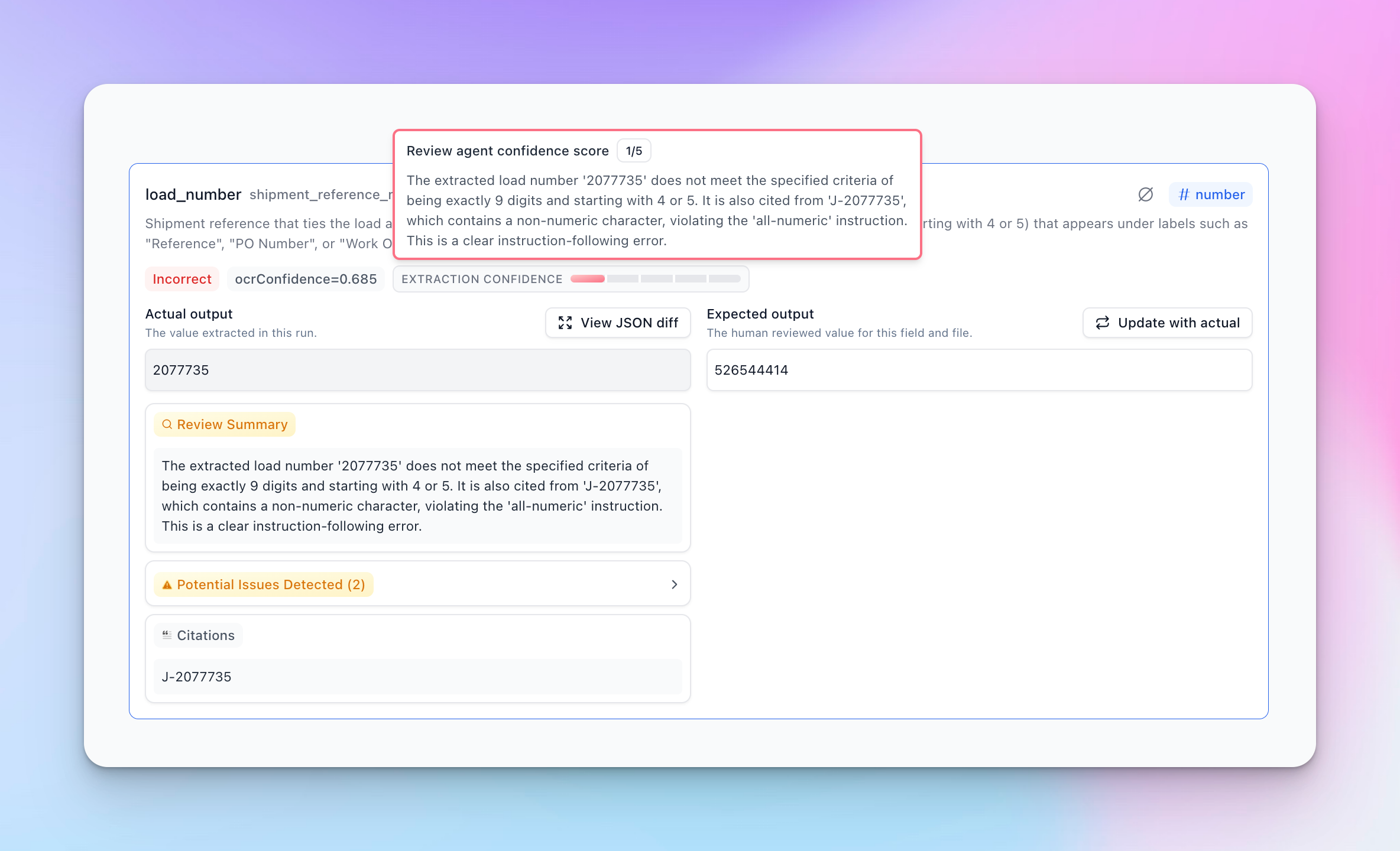
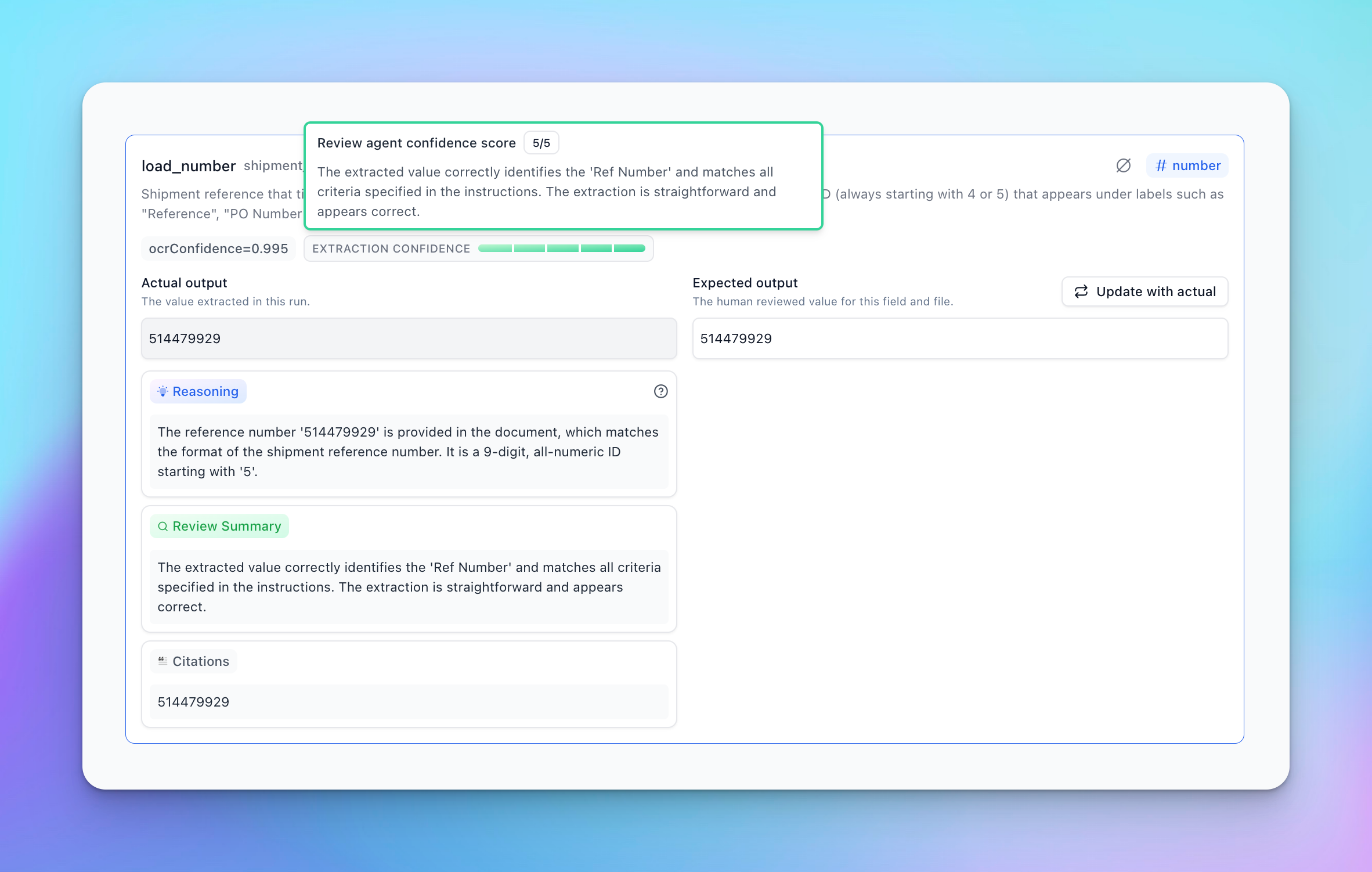
Review Agent automatically detects and scores issues in extraction by reviewing extractions with a critical lens. It flags potential problems such as rule following, ambiguous responses, incorrect extractions, and more, with a confidence score of 1-5.
Key capabilities:
- Ensemble of different metrics for comprehensive trustworthiness assessment
- Automatic detection of rule violations and ambiguous extractions
- User-defined rules to steer quality assurance towards specific flags
- Granular confidence scoring at the field level
New Base Extraction Version
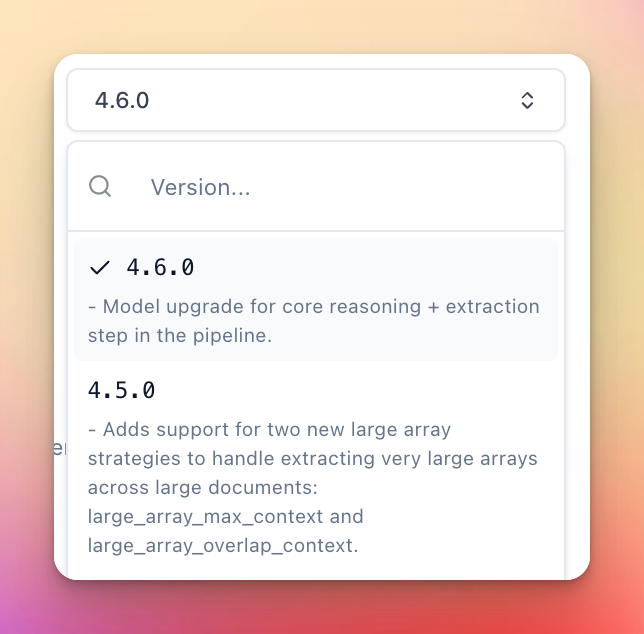
We’ve released several new base extraction versions since last month:
4.6.0- Rolls out a new foundation model that is a major performance improvement for all extraction tasks based on our internal benchmarks, especially for tasks that require more visual reasoning and generating long sequences of text.4.5.0- Adds support for two new large array strategies to more declaratively handle extracting very large arrays across very large documents:large_array_max_contextandlarge_array_overlap_context.
See full changelog here.
New Large Array Extraction Strategies
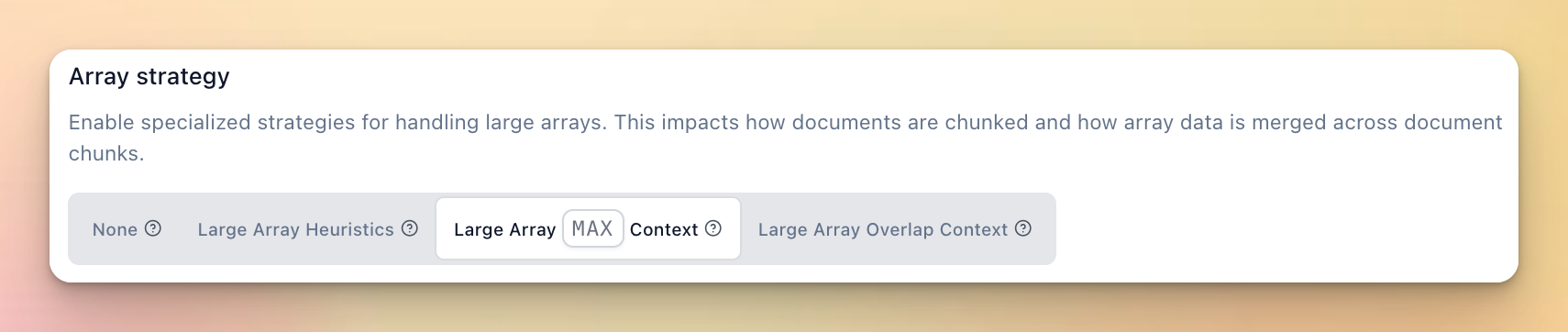
Building on last month’s array strategy controls, we’ve added new extraction strategies for even more flexibility in how arrays are processed.
New advanced large array strategies:
large_array_max_context: Multiple passes through the entire document to ensure there is no context loss across any chunks/pages, maximizing accuracy for complex array extraction, but adding material latency.large_array_overlap_context: Always maintain surrounding/overlapping page context for every chunk/page that is extracted, eliminating most potential array failure modes from context loss across page boundaries.
The MAX context option in particular is a major improvement for accuracy on highly complex, large array/table extraction tasks.
Array Citation Strategy
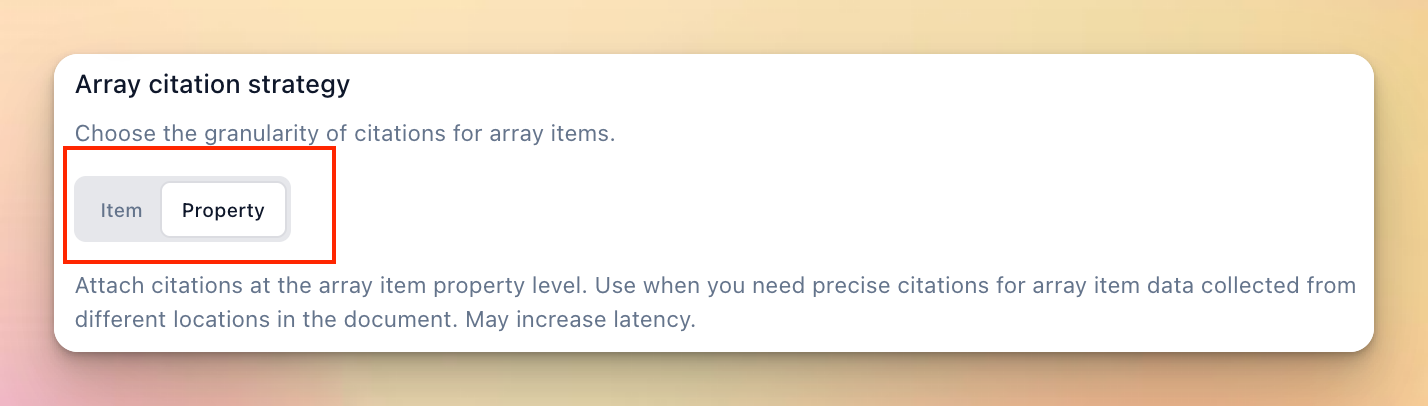
You can now configure the granularity of citations for extracted arrays, with the ability to choose between item or property level citations.
itemlevel citations are the default and will return a citation for each item in the array. Essentially “row” level citations if extracting from a table.propertylevel citations will return a citation for every leaf property of every item in the array. Essentially “cell” level citations if extracting from a table.
Other Wins
Extraction Best Practices Guide
We’ve published a comprehensive best practices guide to help you get the most out of Extend. We will be adding a lot more content to this guide in the coming weeks, but for now it covers:
- Best practices for schema design
- Best practices for latency sensitive use cases
- Comprehensive deep dive into all the advanced extraction options available in Extend
If there are any topics you’d like to see covered in the guide, please let us know!
Refreshed Studio UX
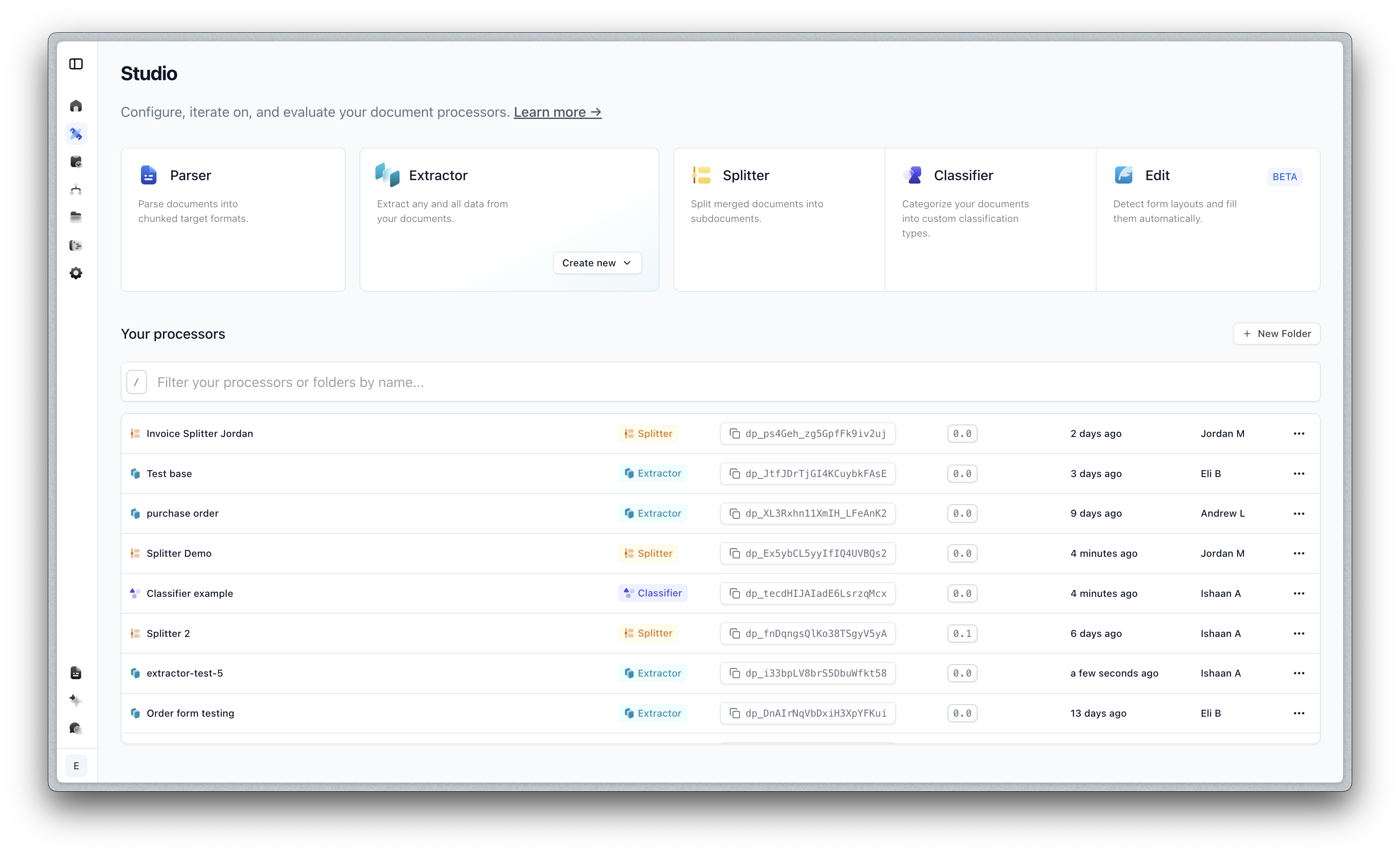
We’ve given the Studio a fresh new look with improved navigation and visual feedback.
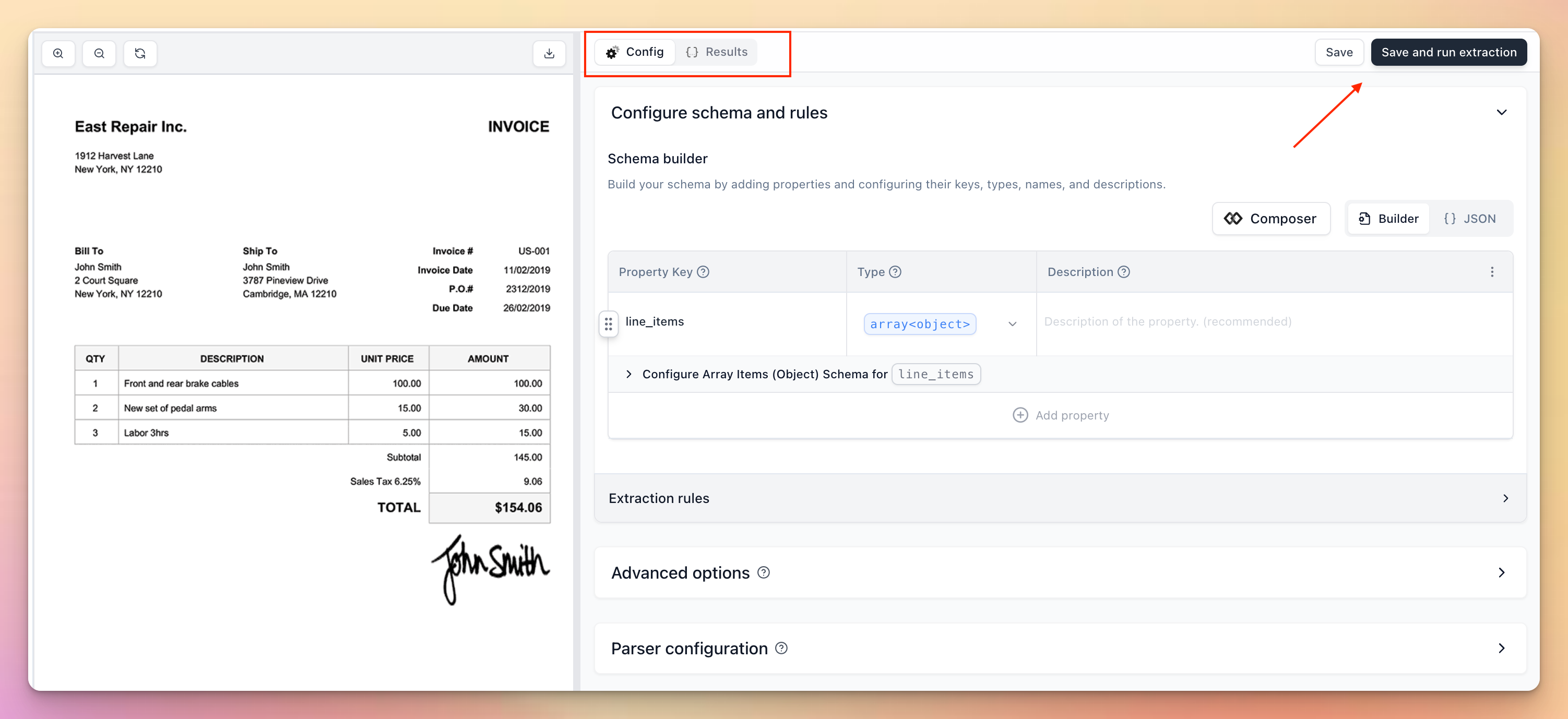
What’s new:
- New animated action cards for better visual feedback
- Color coded tags for easier organization
- New “Created by” column for better collaboration tracking
- Separate tabs for Config and Results for cleaner workflows
Refreshed Home Page
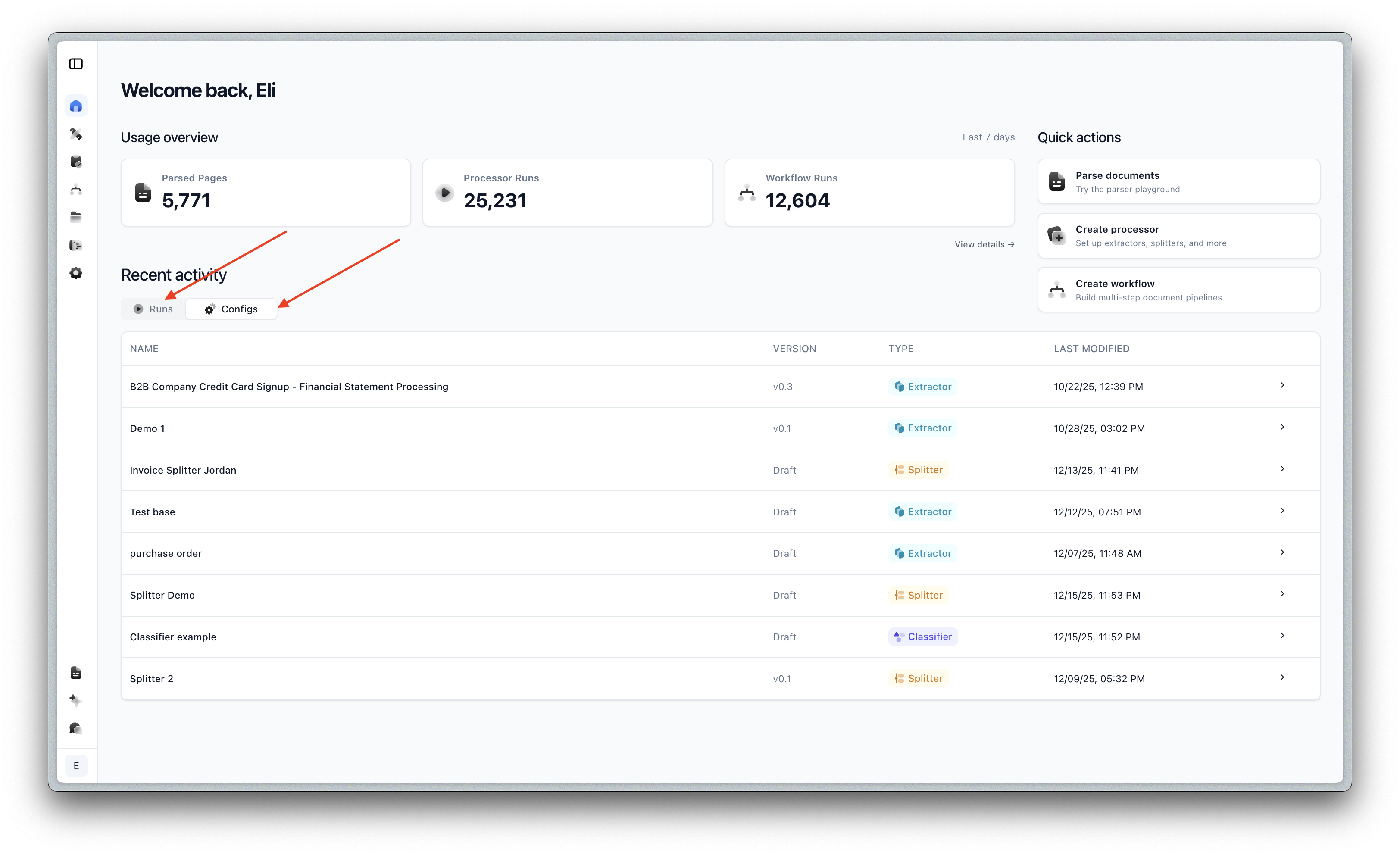
The home page now provides a unified view of your recent activity:
- All the most recent runs (parse/extract/split/workflow/etc) in one place
- Recent config updates at a glance
- Stylistic improvements to the UI