Stay up to date on what’s shipping in the Extend platform.
Extraction Performance 4.8.0
Extraction Performance 4.8.0 is now the latest base processor version. It upgrades the base models used for core extraction and large array strategies
Include a reference date in extraction prompts
You can opt in to an advanced extraction setting that adds a fixed “current date” line to the system prompt. The model can use it when a field depends on today, relative phrases like “30 days from now”, or ambiguous short dates on the page (for example interpreting 02/03/26). The value is taken from when the run was created in UTC.
The option is off by default. For API version 2026-02-09, set advancedOptions.currentDateEnabled to true. See the JSON Schema extraction guide for how advanced options fit into your setup.
Detailed credit breakdown on run responses
Run objects now include richer usage metadata so you can see how credits relate to underlying work alongside the billed amount (credits). The existing usage.credits value is unchanged. For full run payloads and webhook events, responses can also include totalCredits, representing all contributing charges for that logical run (for example extraction plus parsing when parsing was billed for that run), and a breakdown array listing each contributing resource type, id, and credit amount.
On list endpoints, summaries include credits and totalCredits but omit breakdown to keep payloads small. Runs written before totalCredits and breakdown were stored may expose only credits; treat totalCredits and breakdown as optional. For background on billing units, see How credits work. For the full object shape, see usage on the extract run response.
Extraction citation mode control (line, word, block)
Extraction citation mode control (line, word, block)
When bounding box citations are enabled on an extractor, you can set citationMode in advancedOptions to line, word, or block so citation polygons match the granularity you want. If you leave it unset, behavior matches what you have today (line-based citation processing plus block overlap handling across supported parse engines).
Extraction pipelines that use the parse 2.0.0-beta engine can now return bounding box citations for extracted values, so you are not limited to older parse versions when you need spatial references.
See Citations for how citations appear on extracted fields.
citationMode— optional; configure in extractor advanced options in Extend Studio or on extractors (line,word, orblock)
Batch Extract and Batch Parse APIs
Two new endpoints make bulk background processing easier:
/extract/batch— queue thousands of files for extraction in the background without running into rate limits./parse/batch— bulk background parse operations.
Splitter Composer
Composer is now available for splitters, so you can optimize them automatically from eval sets. Previously, Composer was only available for extractors and classifiers.
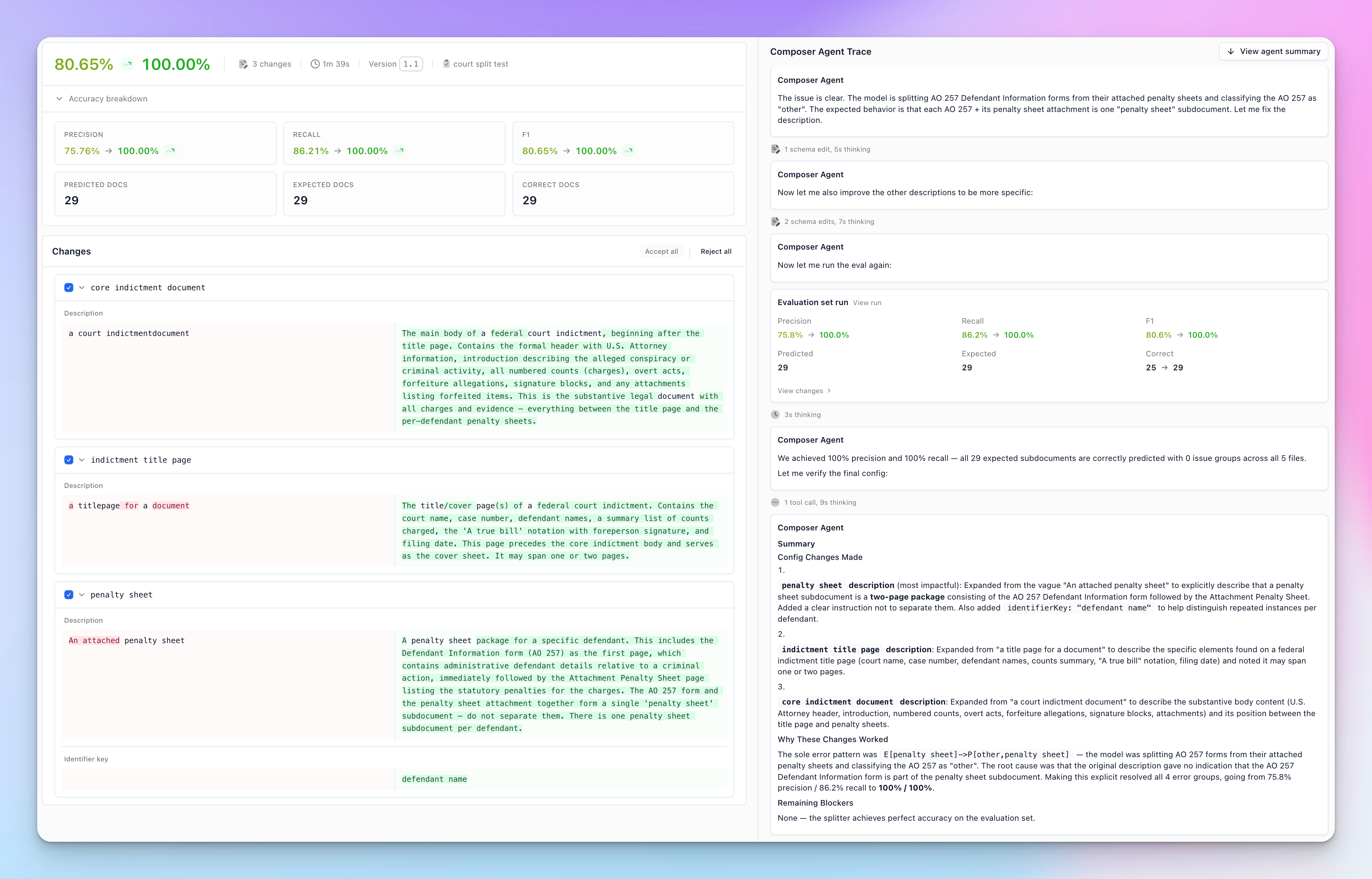
If you’re working on splitting, check out our Splitter Benchmark to see how we evaluate models.
Formula handling in Parse
The new parse engine can now parse formula blocks as LaTeX. Enable it as an advanced option to extract math content directly from documents.
Strikethrough detection in Parse
The new parse engine now detects and annotates strikethrough text via a specialized model. Enable it as an advanced option in the parser config.
Workflows create/update API
Workflows create/update API
You can now create, update, and delete workflows and workflow versions entirely via API. Previously, workflows could only be managed in the Extend dashboard. This makes it easier to generate workflows programmatically, check configs into code, manage them with CI/CD, and build them with agents like Claude Code.
See the full documentation.
Edit: schema generation API
Edit: schema generation API
The form detection and schema generation we offer in Studio is now available as a standalone API, making it faster to create forms and templates for known document types.
See the API reference.