- Classifier Memory
- Enhanced Evaluation Capabilities
- Redesigned Review UI
- Array Strategy Control & Chunking Updates
- Schema Drift Detection with Composer
- EU Deployment & Simplified Self-Hosting
- Other Wins
- Extended Page Limit for Parse API
- Improved Composer Extraction Agent and Trace UI
- Long-Tail File Type Support
- API Logs UI
- Fine-Grained Usage Breakdown
- Status Page
Classifier Memory, Array Strategy Control, LLM Judge Evaluations, New Review UI, and more

We’re excited to share our latest updates that make document processing smarter, more flexible, and easier to review than ever before:
- 🧠 Classifier Memory - Train your Classifiers with unbounded historical examples and context
- ⚖️ Enhanced Eval Capabilities - Run evaluations with LLM-judge, vector matching, and save presets for consistent testing, aggregate accuracy metrics, and more
- ✨ Redesigned Review UI - Better comparison views, new table ui, keyboard shortcuts, and more
- 🔥 Array Strategy Control - More control over array extraction/chunking behavior
- 🔄 Schema Drift Detection - Automatically detect and fix schema changes in eval sets with Composer
- 📄 Larger PDF Page Limits and New File Types
- 🇪🇺 EU Deployment & Self-Hosting Revamp - More deployment flexibility to use Extend according to your compliance requirements
- And much more…
Let’s dive in!
Classifier Memory
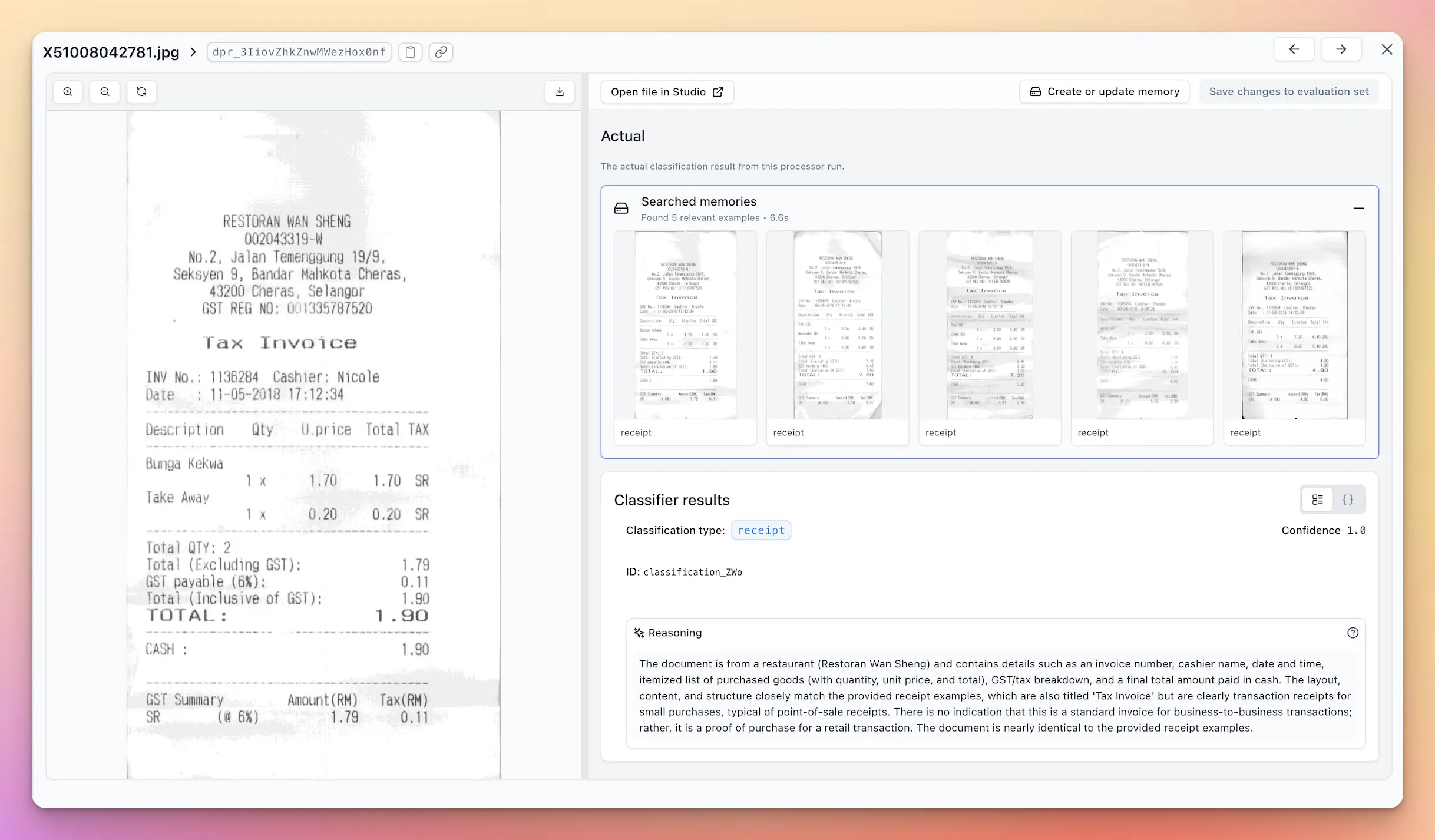
Memory serves as a generic, flexible, and scalable primitive for example based improvements to your processors, starting with Classifiers.
Why do you need it?
- Prompting has a lot of limitations and is not complete context in many types of tasks, especially classification and splitting.
- For document similarity in a given use case, visual/layout information is the most reliable indicator of a similar example
When enabled, your Classifier will find and use the most similar historical examples to guide its decisions on new documents, resulting in more consistent and accurate classifications over time.
View the full guide on how it works and how to use it here.
Enhanced Evaluation Capabilities
We’ve supercharged our evaluation system with powerful new testing options to help you measure and improve accuracy with more precision.
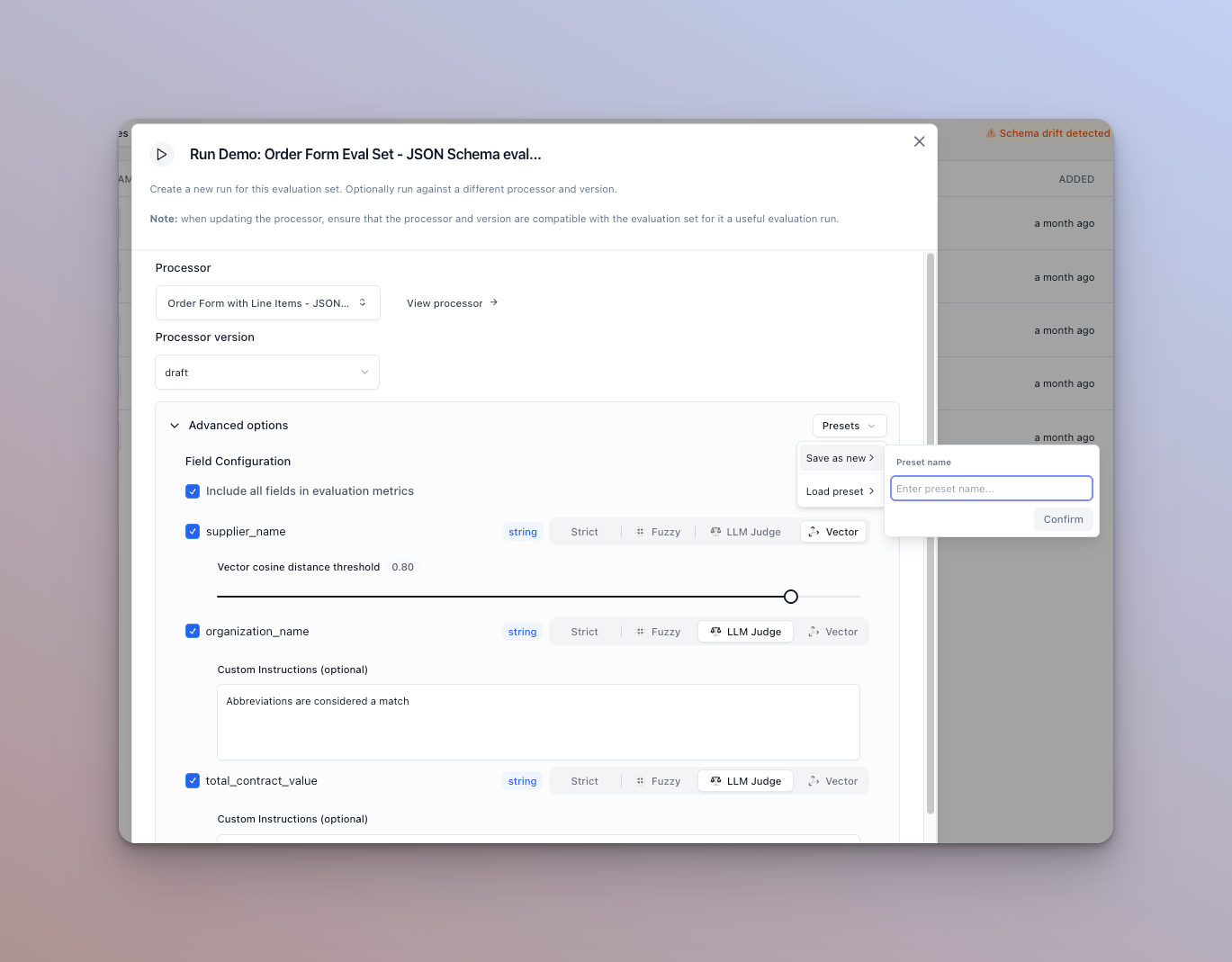
New evaluation comparison options:
- llm-as-judge with custom instruction
- vector (embeddings based) matching
- controllable fuzzy score
We also added the ability for you to save these configs as a preset for easy reuse in future runs.
Redesigned Review UI
We’ve completely redesigned our extraction review interface for a more intuitive and efficient review experience.
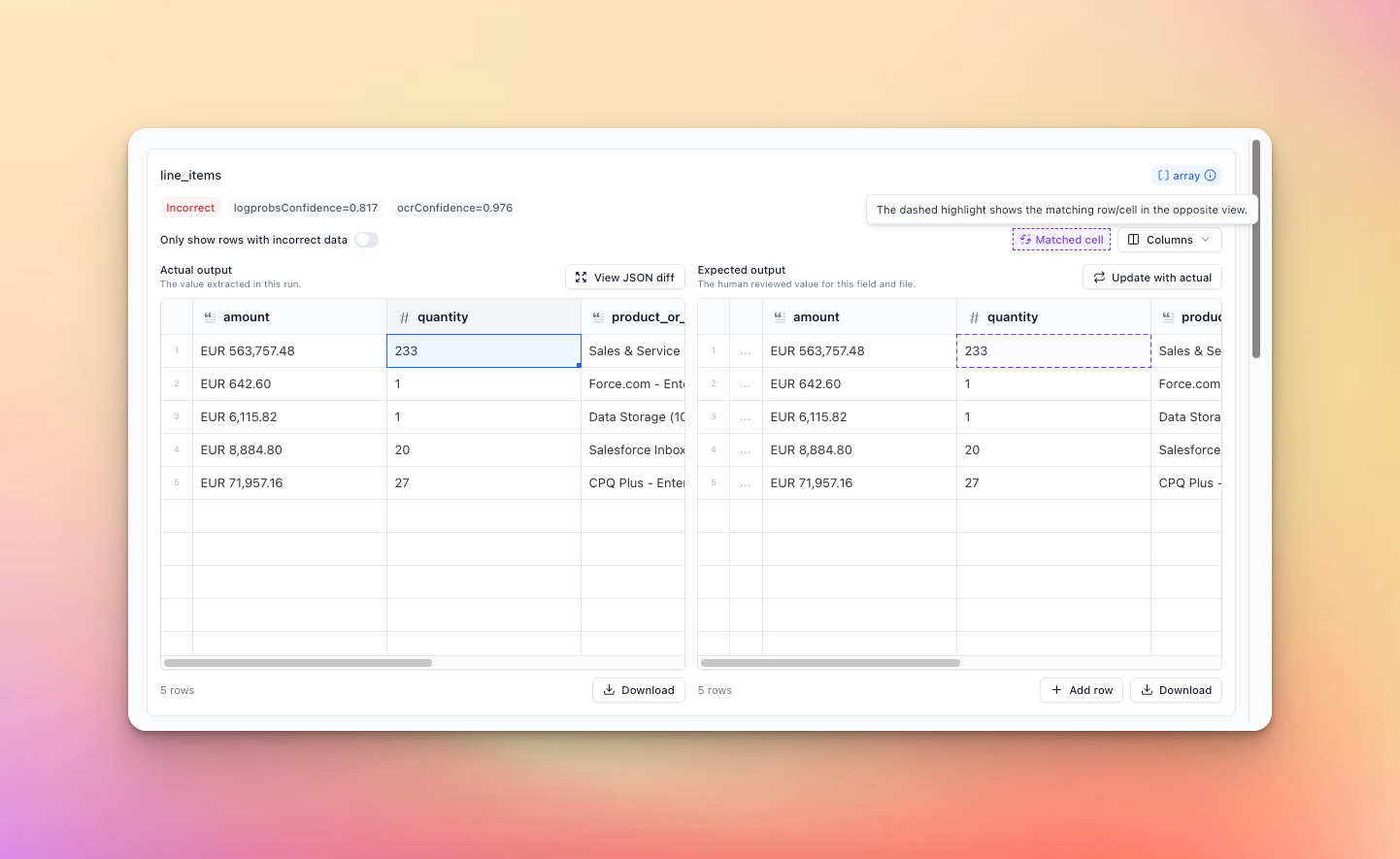
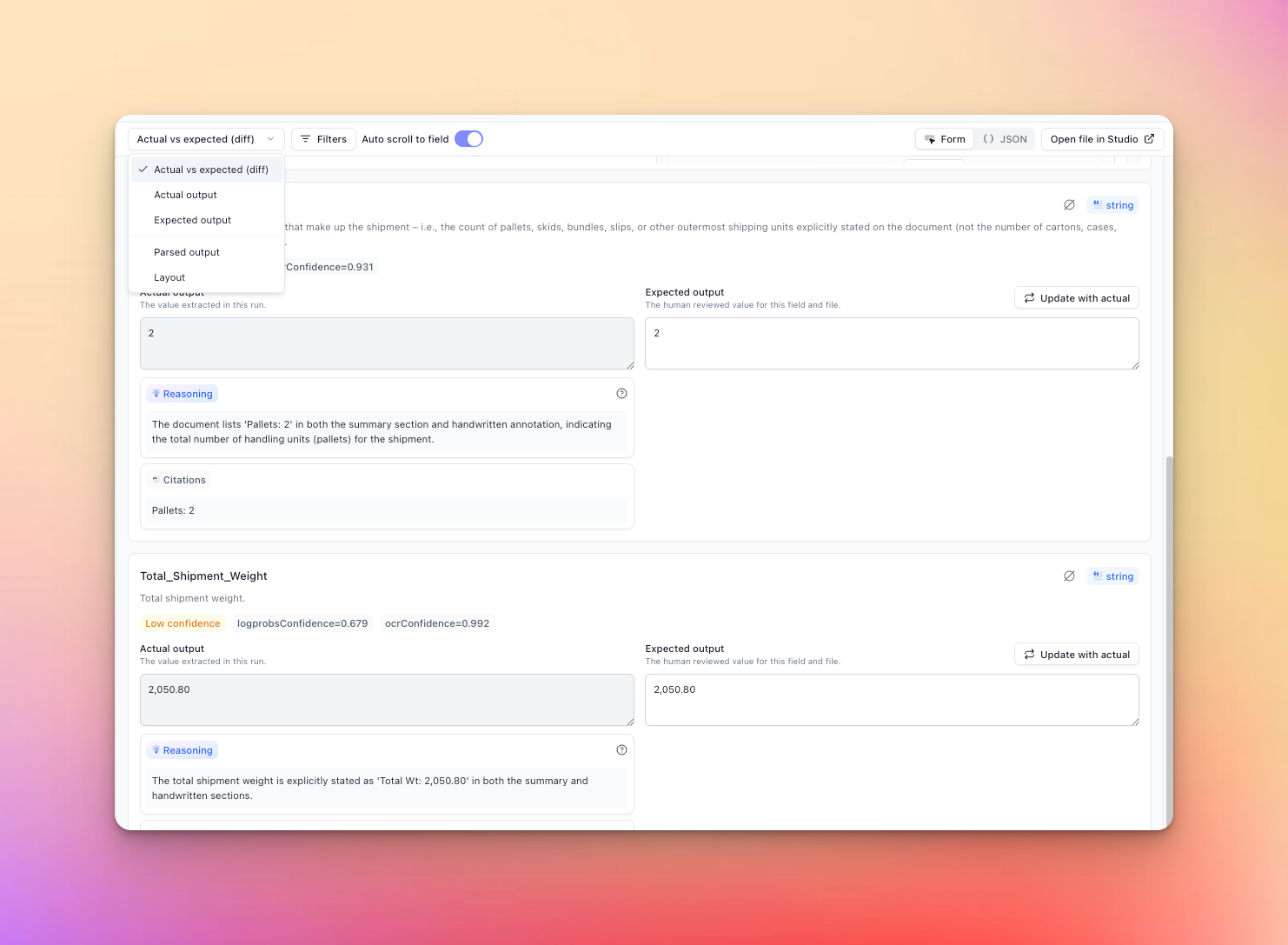
What’s new:
- Side by side result comparison
- Toggles to control form vs. json in any view
- Select output vs. expected, expected only, actual only, parse view etc
- New table component for much better editing/reading of large arrays
- A bunch of nice keyboard shortcuts to navigate and edit the review UI
Array Strategy Control & Chunking Updates
Currently our extraction system does dynamic chunking and merging of extracted content that applies custom heuristics to handle array fields. This works great, but some times you want more control opting into this depending on the type of array.
Now you can specifically opt into “large array heuristics” which is a specialized strategy for handling very large arrays. Leaving the default chunking and intelligent merging for basic arrays (e.g. listing names, codes, etc)
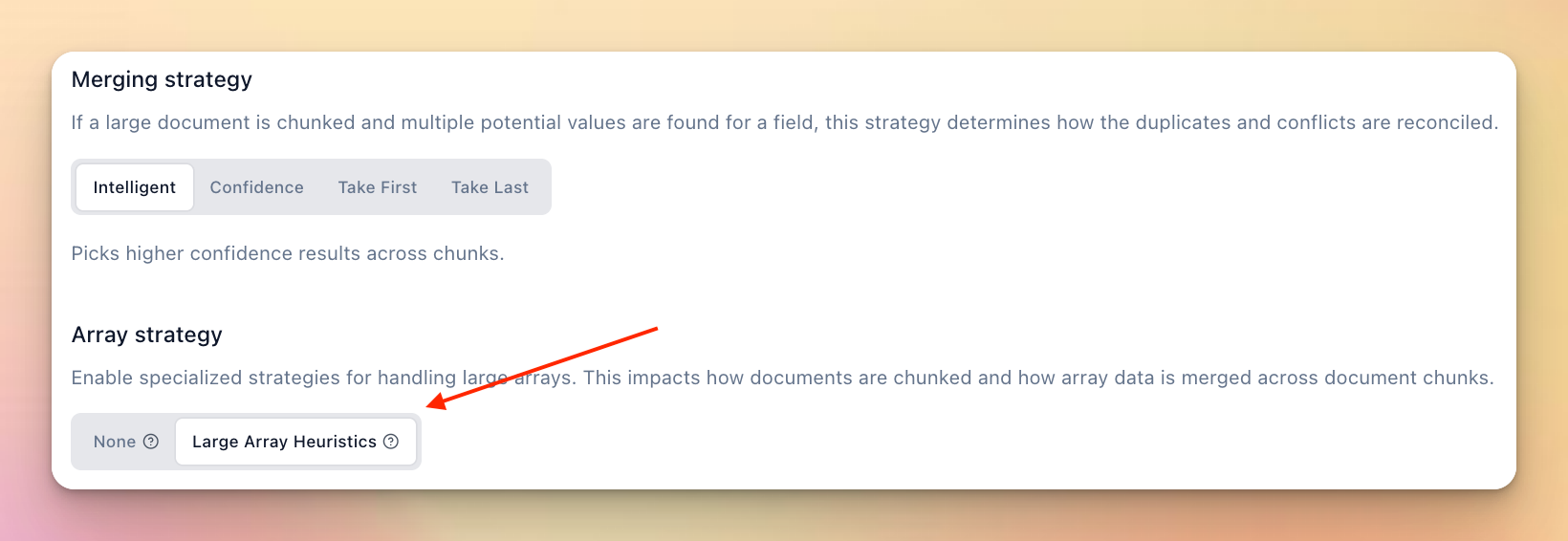
Available in json-schema based extraction processors on v4.2.1 or higher.

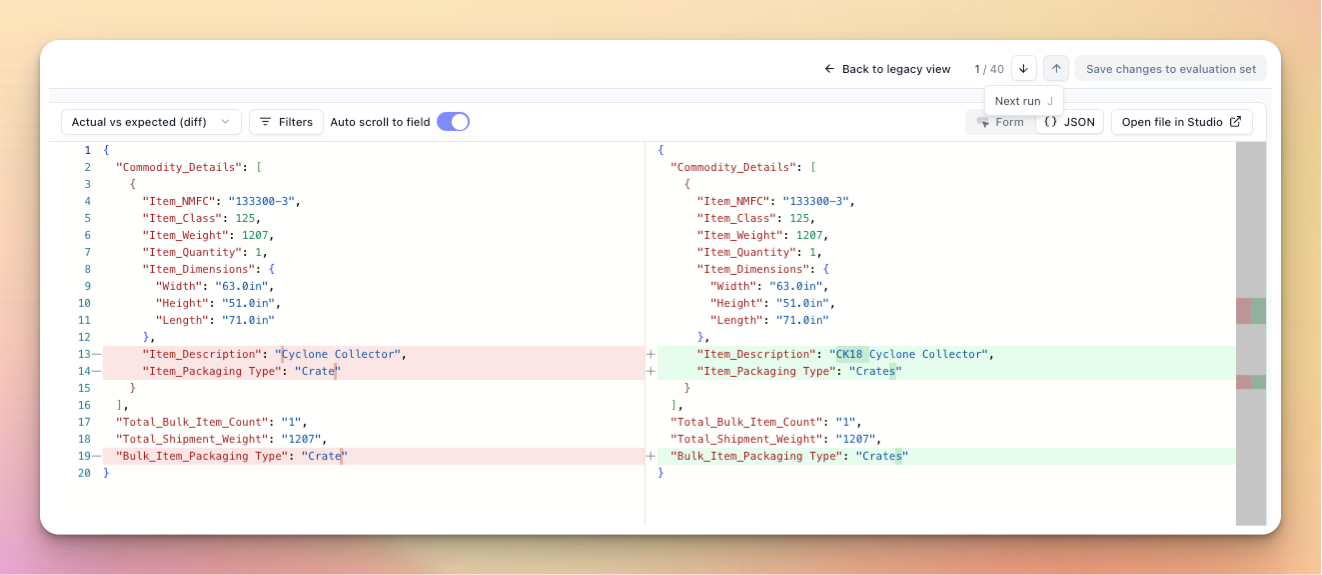
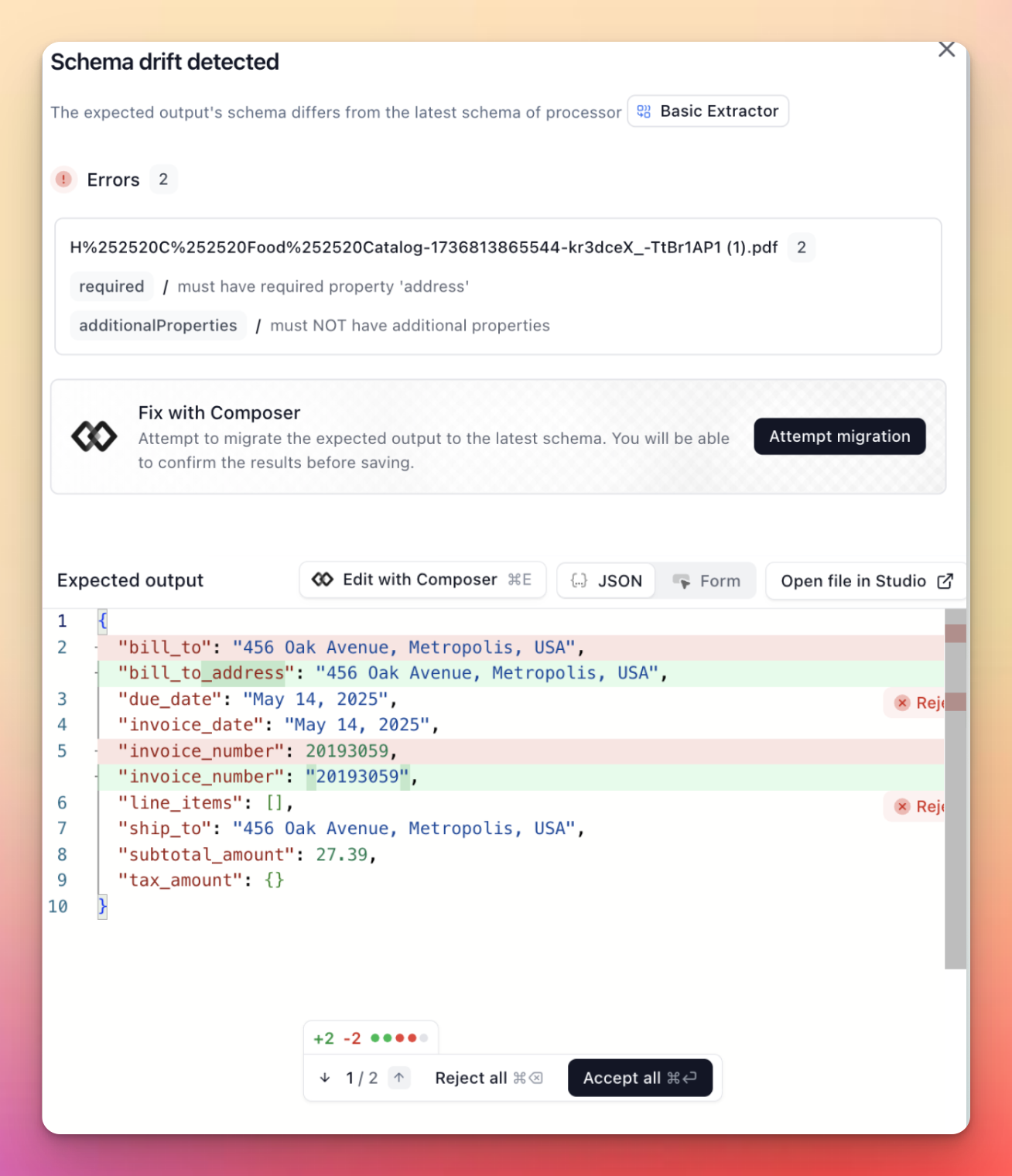
Schema Drift Detection with Composer
Composer now automatically detects when your schema has drifted from your evaluation data and can fix it for you.
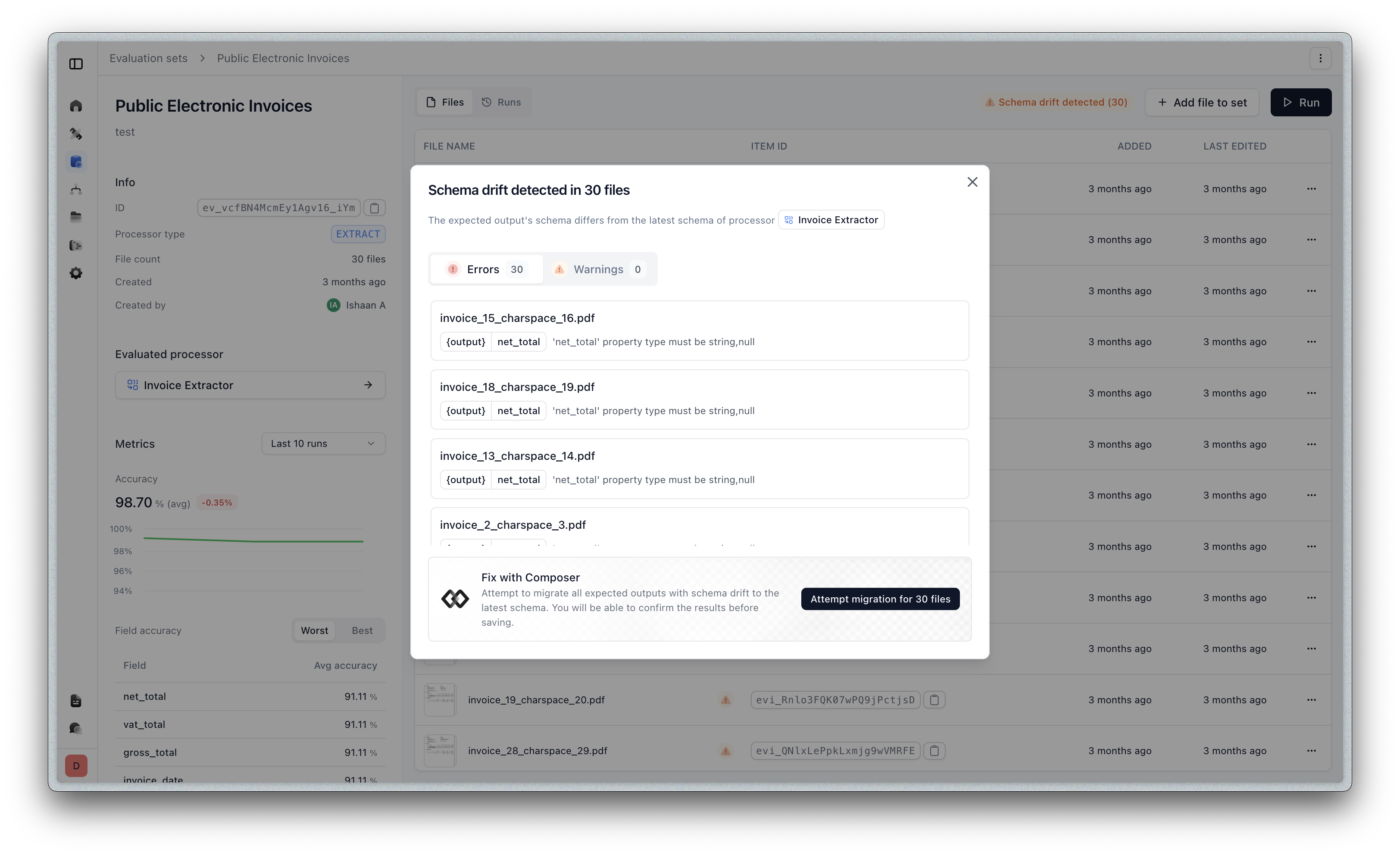
Extend will auto flag detected schema drift across files in your evaluation set, and you can use Composer to fix all or a given file:
EU Deployment & Simplified Self-Hosting
We now have a fully compliant EU deployment! If you’re an existing EU based customer, reach out if you’d like to migrate to the EU endpoint. If you’re a prospective customer that requires EU data residency, please reach out!
We also did a significant re-working of our internal infrastructure setup to enable much easier self-hosting or “bring your own cloud” deployment options. On top of that, we’ve simplified our pricing to self-hosting. Reach out if you’d like to learn more!
Other Wins
Extended Page Limit for Parse API
The Parse API now supports documents up to 1,250 pages, a significant increase from previous limits.
Improved Composer Extraction Agent and Trace UI
We’ve added a new extraction agent and improved the trace UI for better visibility into optimization processes.
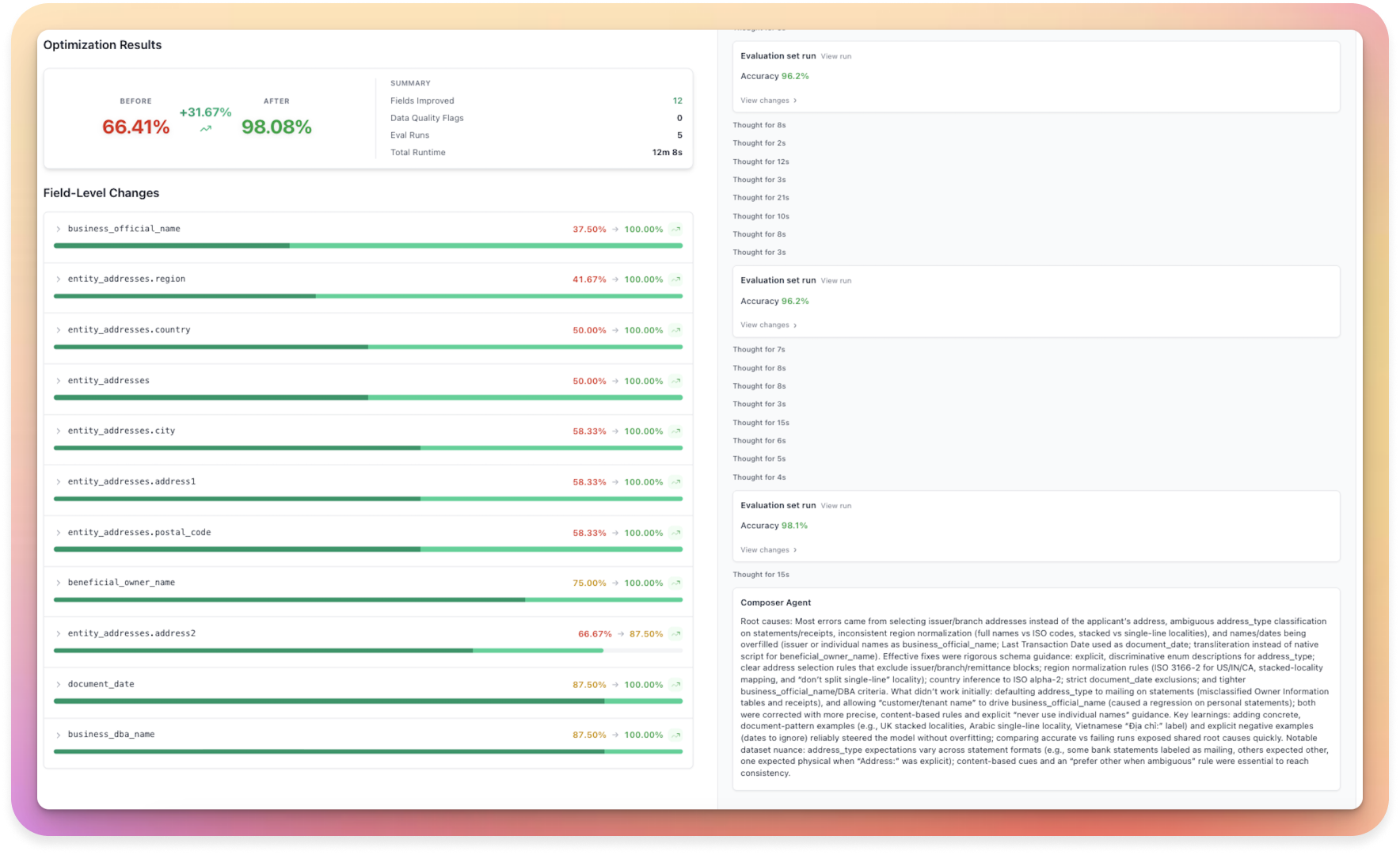
What’s new:
- Last month we rolled out a new extraction Composer agent that is faster and can handle more complex/large schemas and documents
- We’ve also improved the trace UI to better reflect the actual actions and reasoning the agent took to optimize your schema
Long-Tail File Type Support
We’ve added support for a wide range of “long-tail” file types!
Newly supported formats:
.gif, .webp, .ppm, .pcx, .psd, .wpd, .dotx, .xltm, .xltx, .bmp, .rtf, .eml,
- All types above supported in extract/split/classify operations
- Only non-text formats supported in Parse API
Full list of supported file types here.
API Logs UI
Track and debug your API calls with our new logs interface in the Developers tab, with new filtering and views.
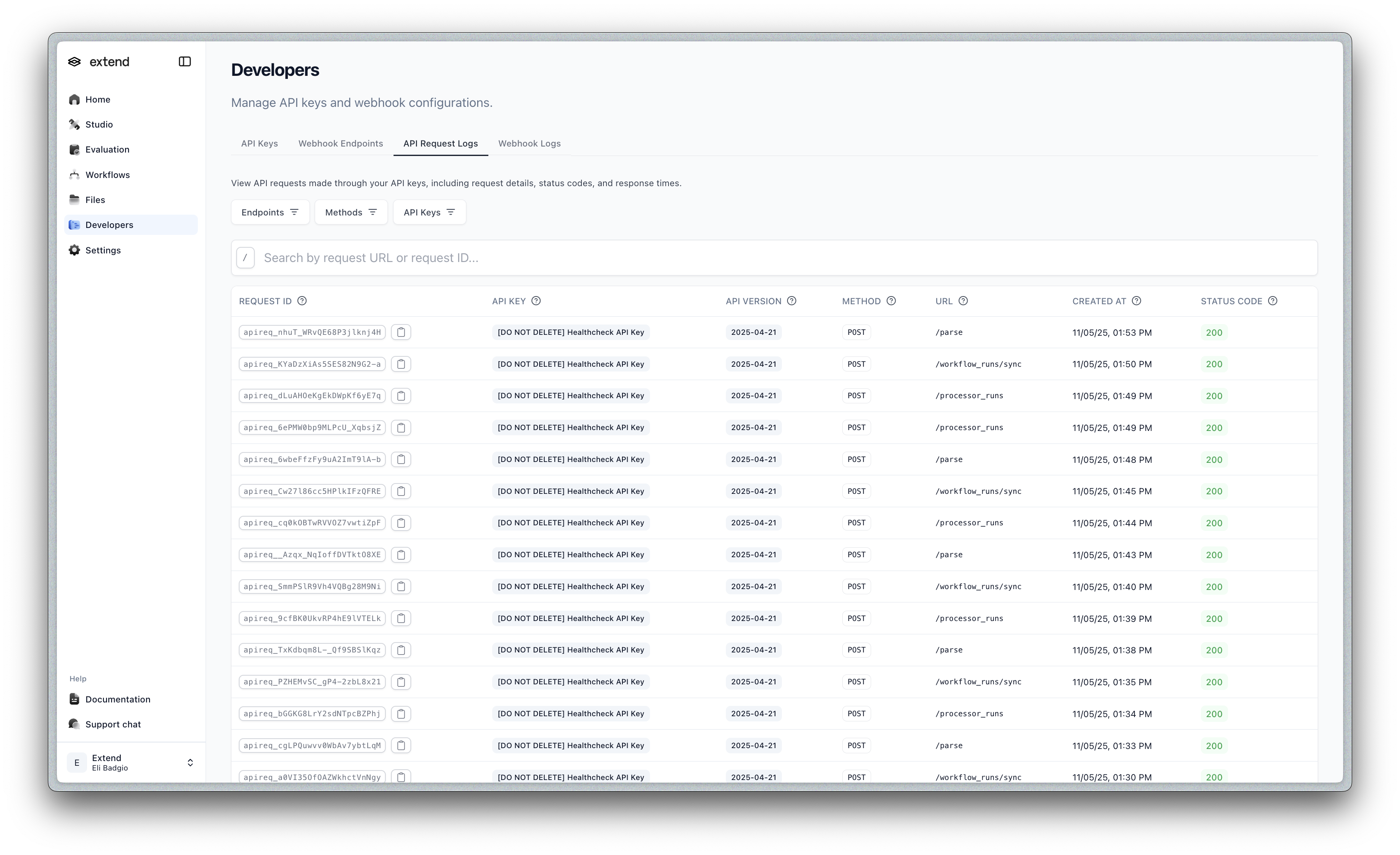
You can also click into any request to view the request and response payloads and other details.
Fine-Grained Usage Breakdown
Get detailed insights into your credit usage with new charts and views
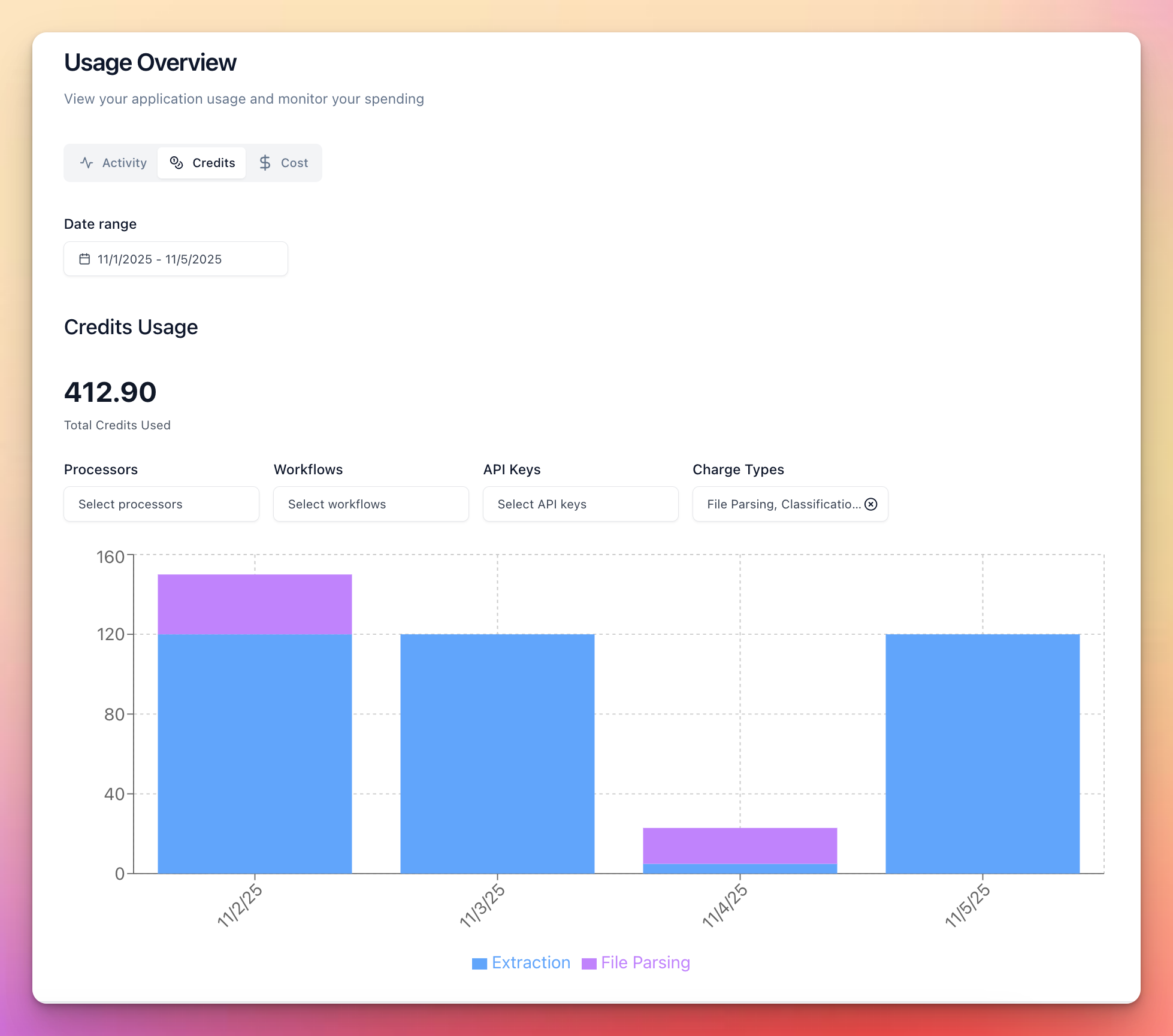
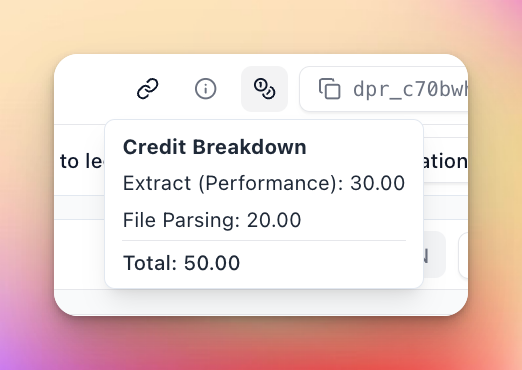
Features:
- Filter by API keys, workflows, and more
- View credit costs on individual run detail pages
Status Page
We’ve launched a dedicated status page to keep you informed about system health and performance.
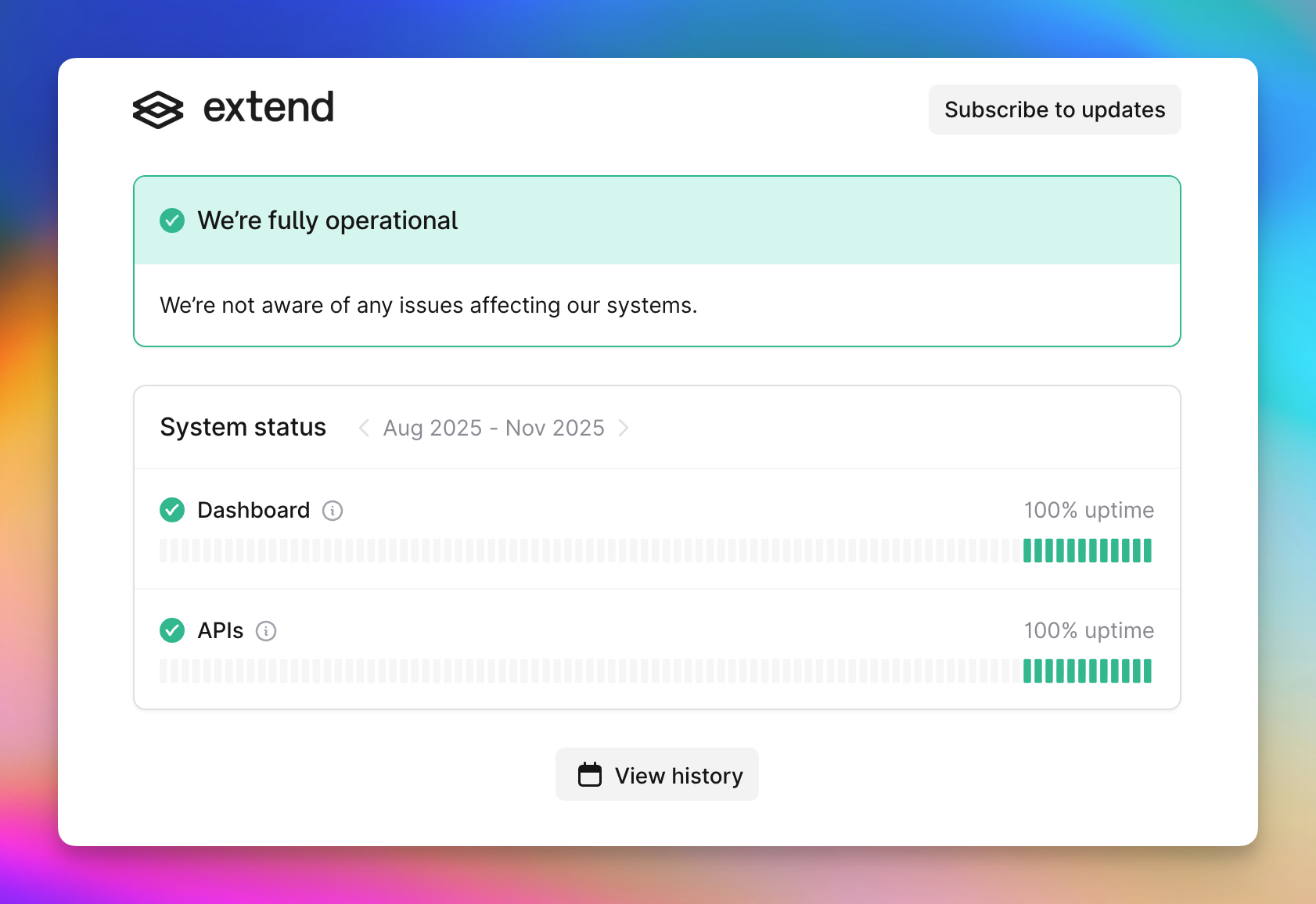
Note: We’ll be adding more fine grained automated monitors that update this page over the coming week.