Memory in Extend enables processors like Classifiers, Splitters, and Extractors to remember and use validated historical results to improve performance on new documents.
Right now it is live in Public Beta for Classifiers, and will be available for Extractors and Splitters in the near future.
Memory enhances your processors by automatically learning from past successful classifications. When enabled, your Classifier will find and use the most similar historical examples to guide its decisions on new documents, resulting in more consistent and accurate classifications over time.
Think of Memory as giving your processor the ability to say: “I’ve seen documents like this before, and here’s how they were correctly classified.”
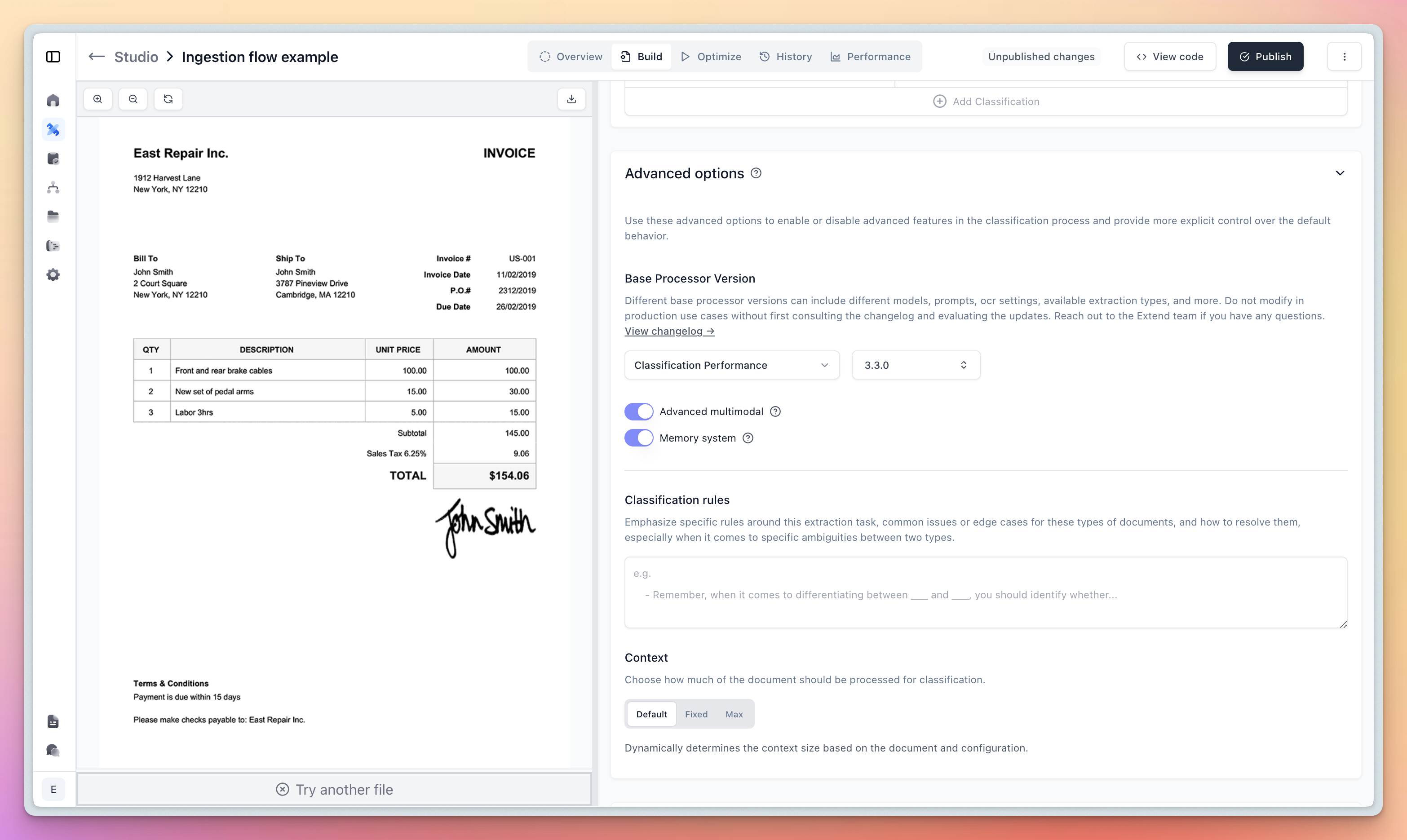
When Memory is enabled for a Classifier:
Automatic Example Collection: Each time you validate a classification result (either through evaluation sets or by correcting outputs), that document becomes a potential example that can help with future classifications.
Retrieval: When processing a new document, Memory uses a mix of multimodal embeddings and other retrieval/search techniques to find the most relevant historical documents.
Contextual Learning: These relevant examples and context are added dynamically to the classifier’s context as it is processing the new document, enabling better decisions based on validated examples.
Continuous Improvement: As you process more documents and validate results, your Memory bank grows, leading to increasingly accurate classifications.
Click the Manage memory button to view and manage your stored examples:
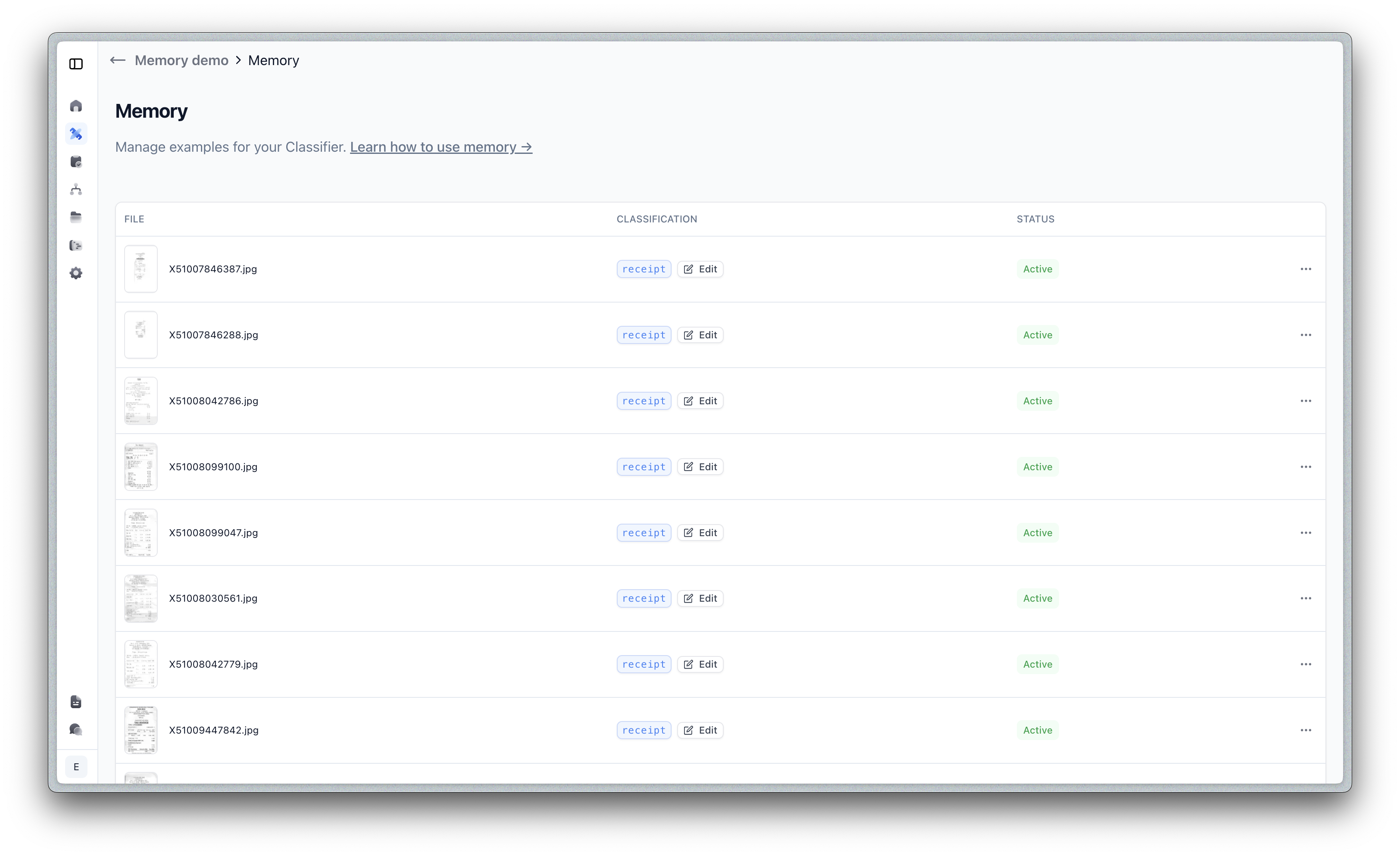
From this interface, you can:
Each example shows:
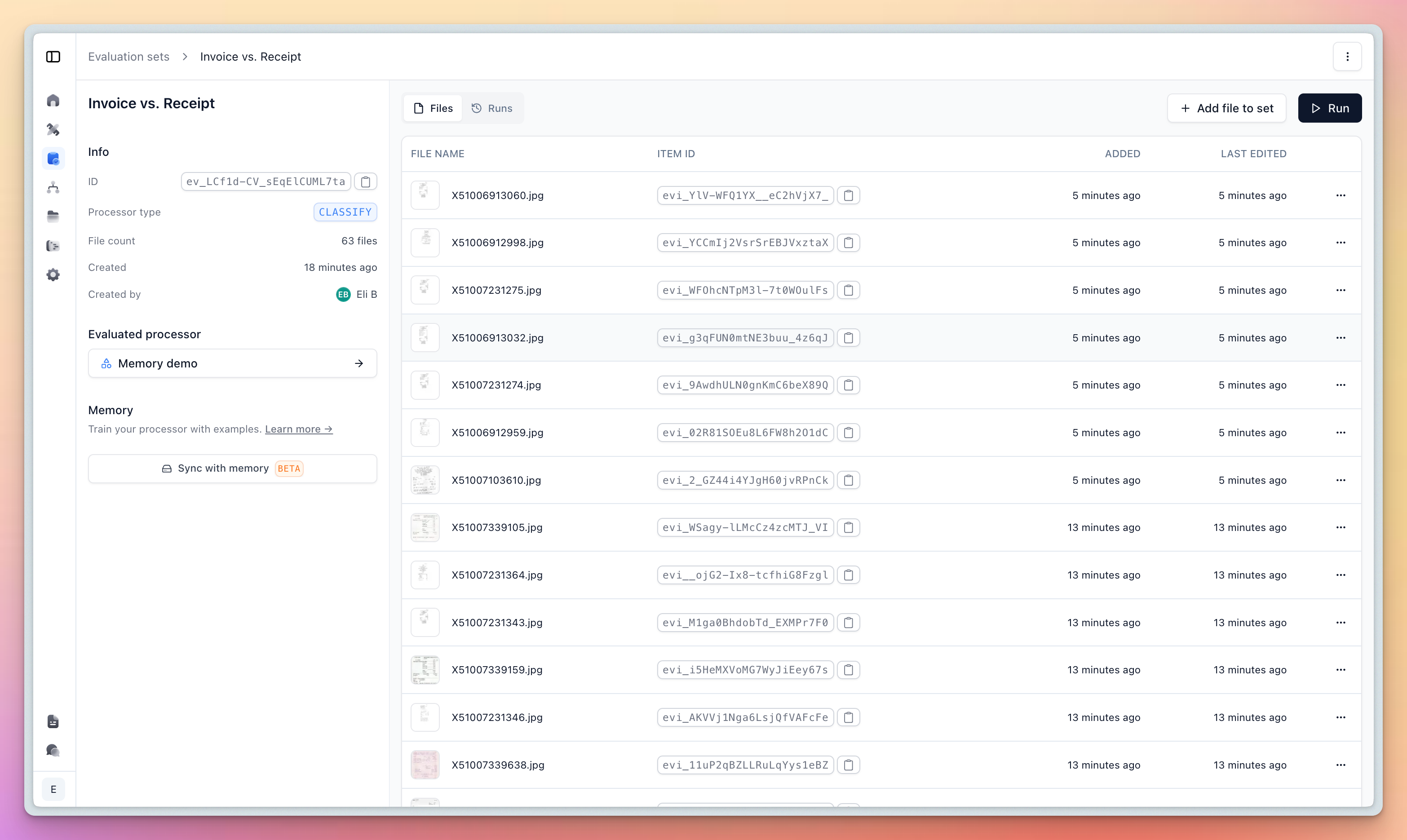
For convenience, you can also create and sync your memory examples directly from evaluation sets.
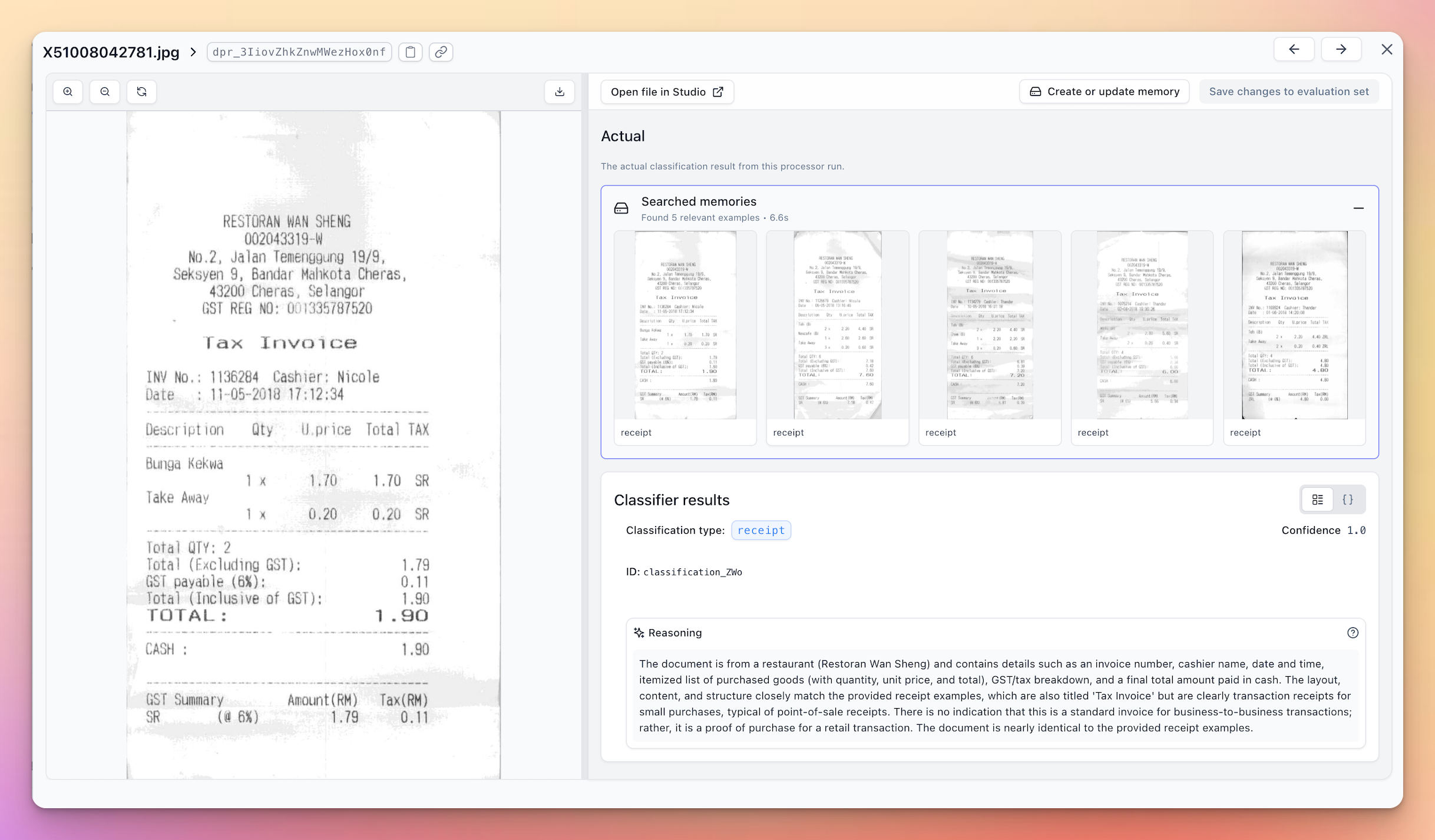
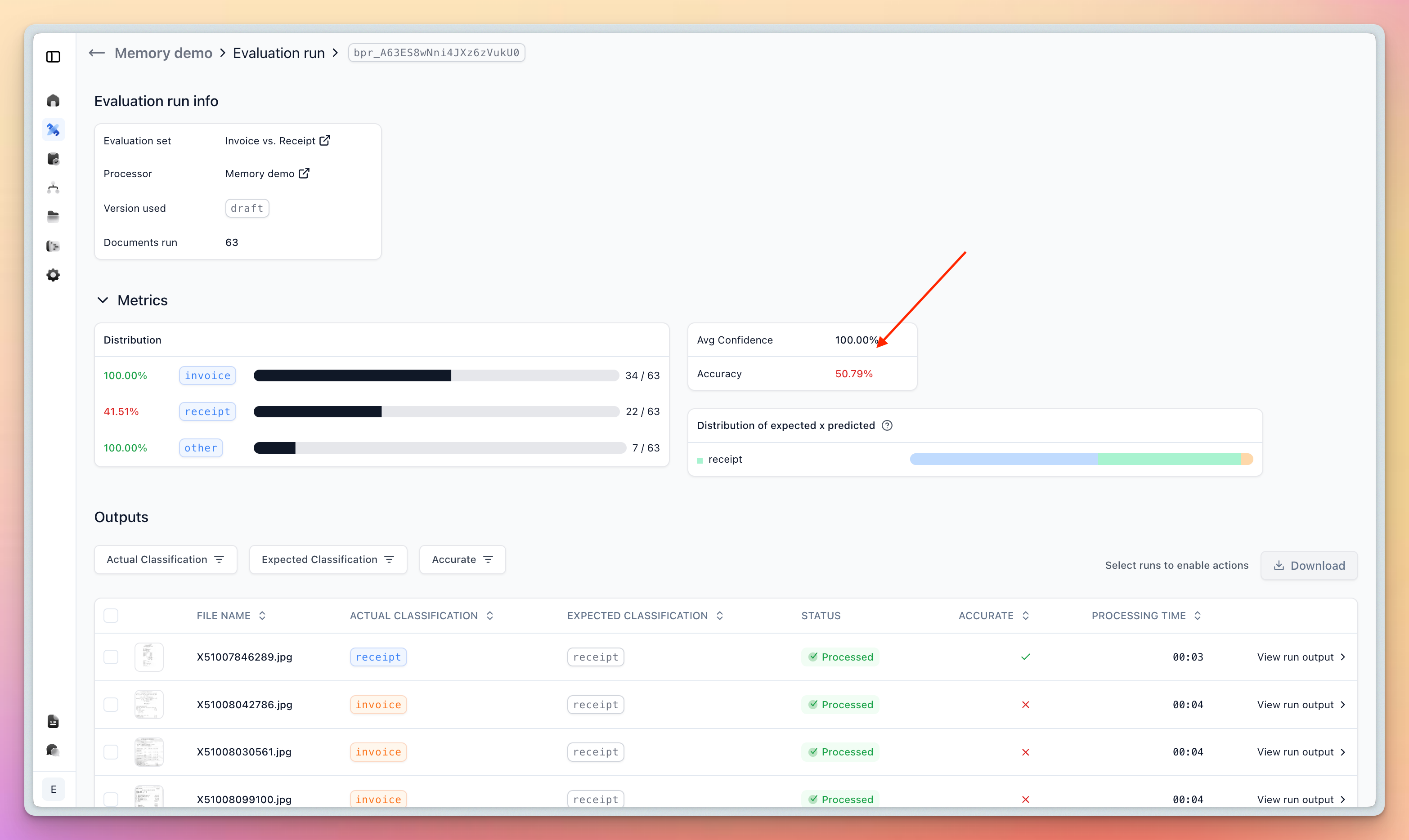
Here’s a real example showing Memory’s impact on classification accuracy:
Before Memory: A standard Classifier might struggle with edge cases, like receipts that look similar to invoices or mention invoice details or say “this is not a receipt” even though in your use case it is one.
After Memory: With Memory enabled and able to see the invoice-like receipts are classified as receipts, the accuracy jumps to 100% on the evaluation set.
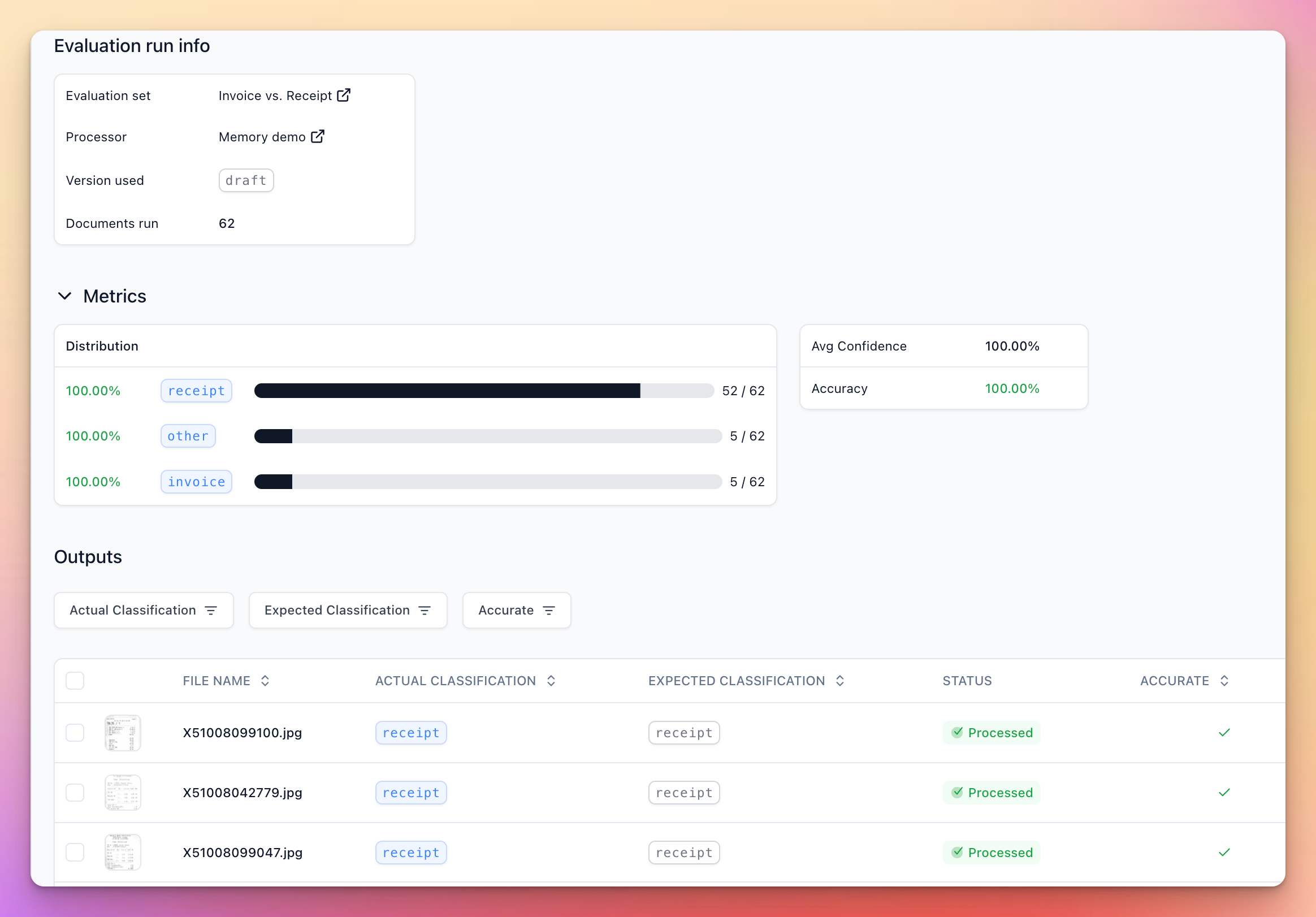
The key improvement comes from Memory understanding the subtle differences in your specific document types. For instance, seeing that even cases that say “this is not a receipt” or mention “Tax Invoice” are receipts in this use case.
The flexibility of Memory also means you can keep adding and removing historical examples as needed and as your system ingests more kinds of documents, without needing to endlessly adjust and write longer prompts.
Both Memory and Composer help optimize your processors, but they work in fundamentally different ways.
Memory will be most useful for classification tasks where the documents are visually similar, but have very subtle differences that are hard to prompt for even when paired with the best reasoning models.
Composer will be most useful when the classification is purely semantics and an Agent can learn the rules and craft robust prompts for a downstream reasoning model.
They often can and should be used together to get the best results: