Extend uses machine learning models to extract information from documents. A confidence score tells you how ‘confident’ the model is about the accuracy of an extracted value. The score is presented as a number between 0 and 1, with values closer to 1 indicating higher confidence.
Below, you can see an example of an extraction with high confidence, and that all of the extracted values are correct.
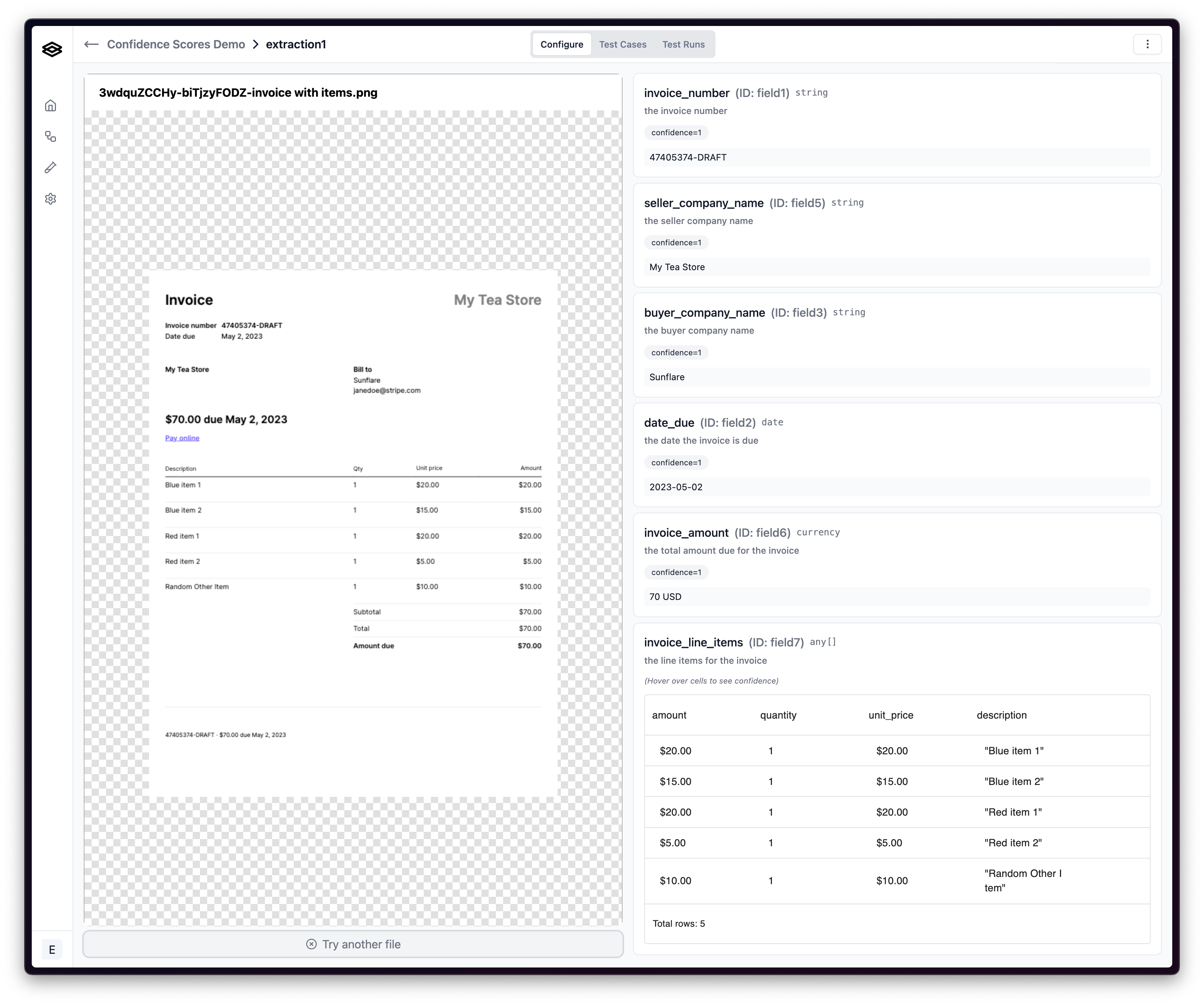
While confidence scores are a valuable tool in assessing the reliability of extracted data, it’s important to recognize their limitations to use them effectively.
A high confidence score indicates a high probability of correctness, but it doesn’t guarantee accuracy. Even with a high score, there’s always a chance of errors, so critical data should always be cross-verified.
Confidence scores are calculated using models and their understanding of the data. They may not account for nuances or context that a human reviewer who understands your business would recognize. Because of this, it’s imperative to supply sufficient context on the value you want extracted so the AI can determine whether it is confident or not.
For example, if you name a field “company_name” on an extractor designed for invoices, the model may not be confident on which name you are asking for as there are a couple different company names on invoices.
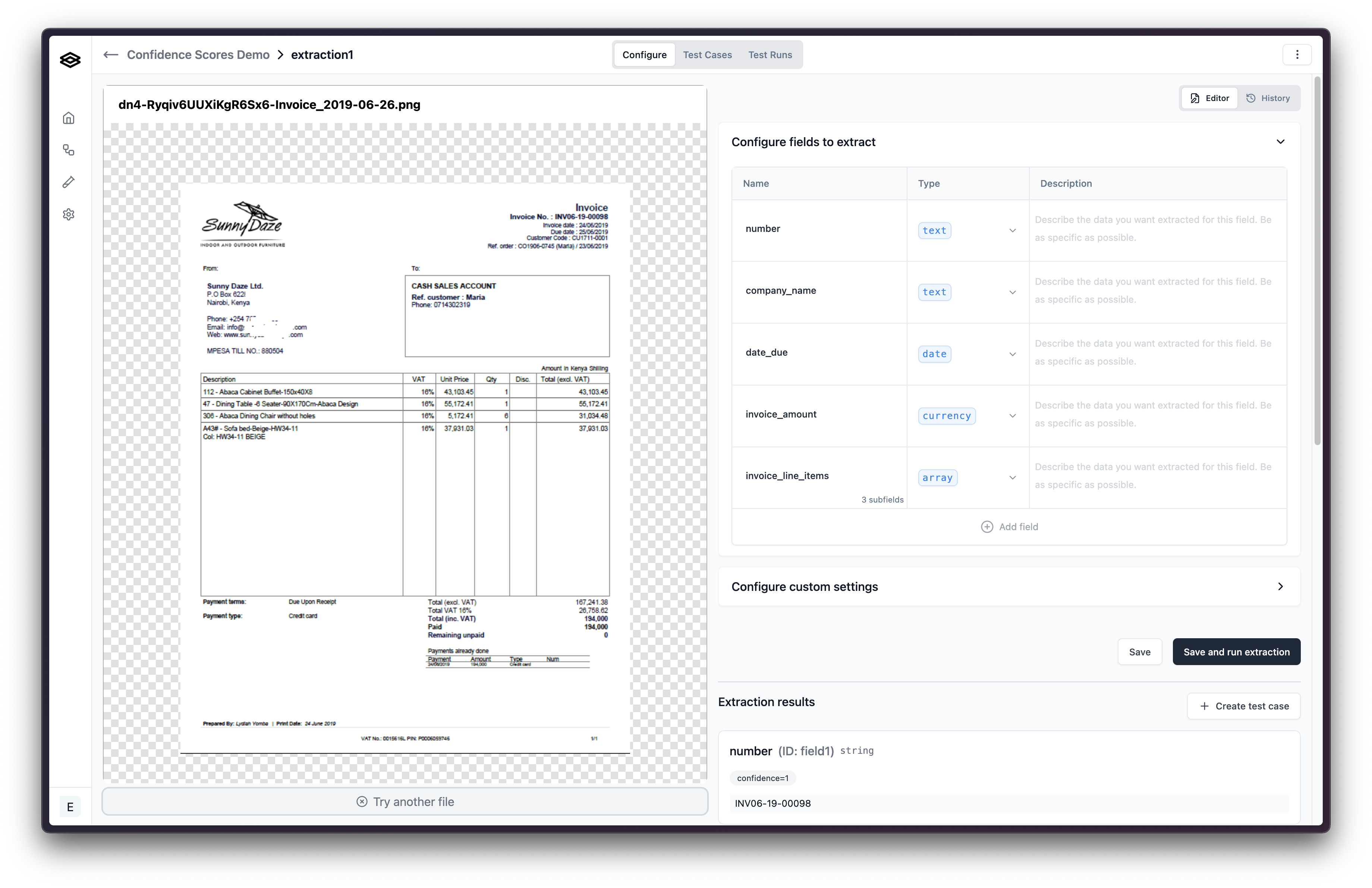
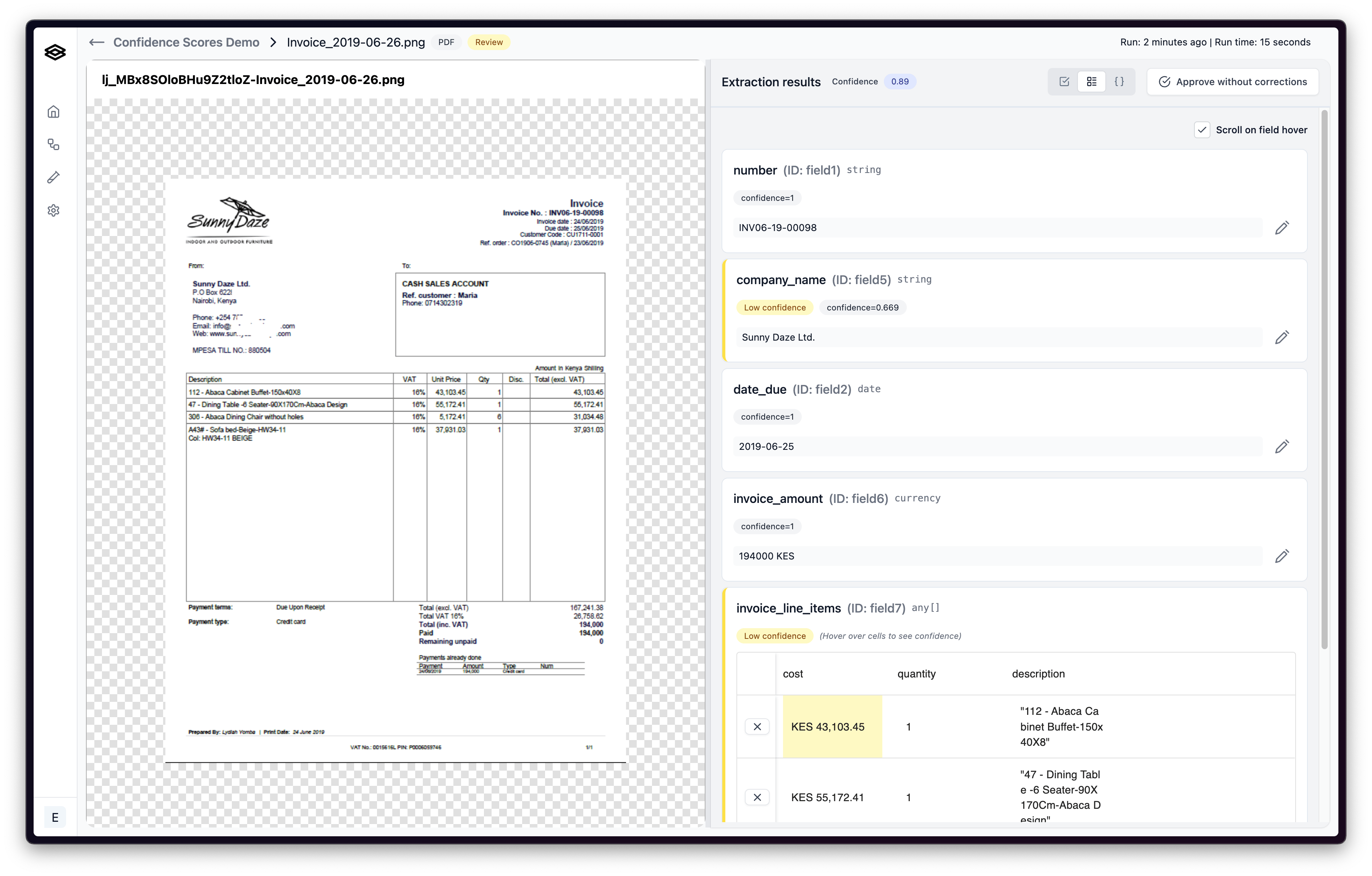
The following usage patterns apply:
Using conditional steps, you can handle a document differently depending on whether its extraction confidence score is above or below a certain ‘confidence threshold’. For instance, if you’re extracting important financial data, you might set a high threshold, accepting only data with confidence scores above 0.95. For less critical data, a lower threshold might be acceptable.
Use confidence scores to prioritize data for review. Data points with low confidence scores might need manual verification or further investigation.
In large datasets, you may want to filter out data below a certain confidence level to ensure the quality and reliability of your analysis.
We provide two types of confidence scores in the metadata object of processor run outputs:
logprobsConfidence - Confidence from the language model based on token probabilities during generationocrConfidence - Confidence from the OCR (Optical Character Recognition) system about text extraction accuracyBoth scores range from 0 to 1, with values closer to 1 indicating higher confidence.
The extraction_light base processor does not support logprobs. As a result:
logprobsConfidence will be null.0.Confidence scores are stored in the metadata object using path-like keys that correspond to your extracted data structure:
We provide several ways to access confidence scores in conditional steps:
Aggregate Confidence Access:
{{extractionStepName.avgConfidence}} - Average confidence across all extracted fields{{extractionStepName.minConfidence}} - Minimum confidence across all extracted fields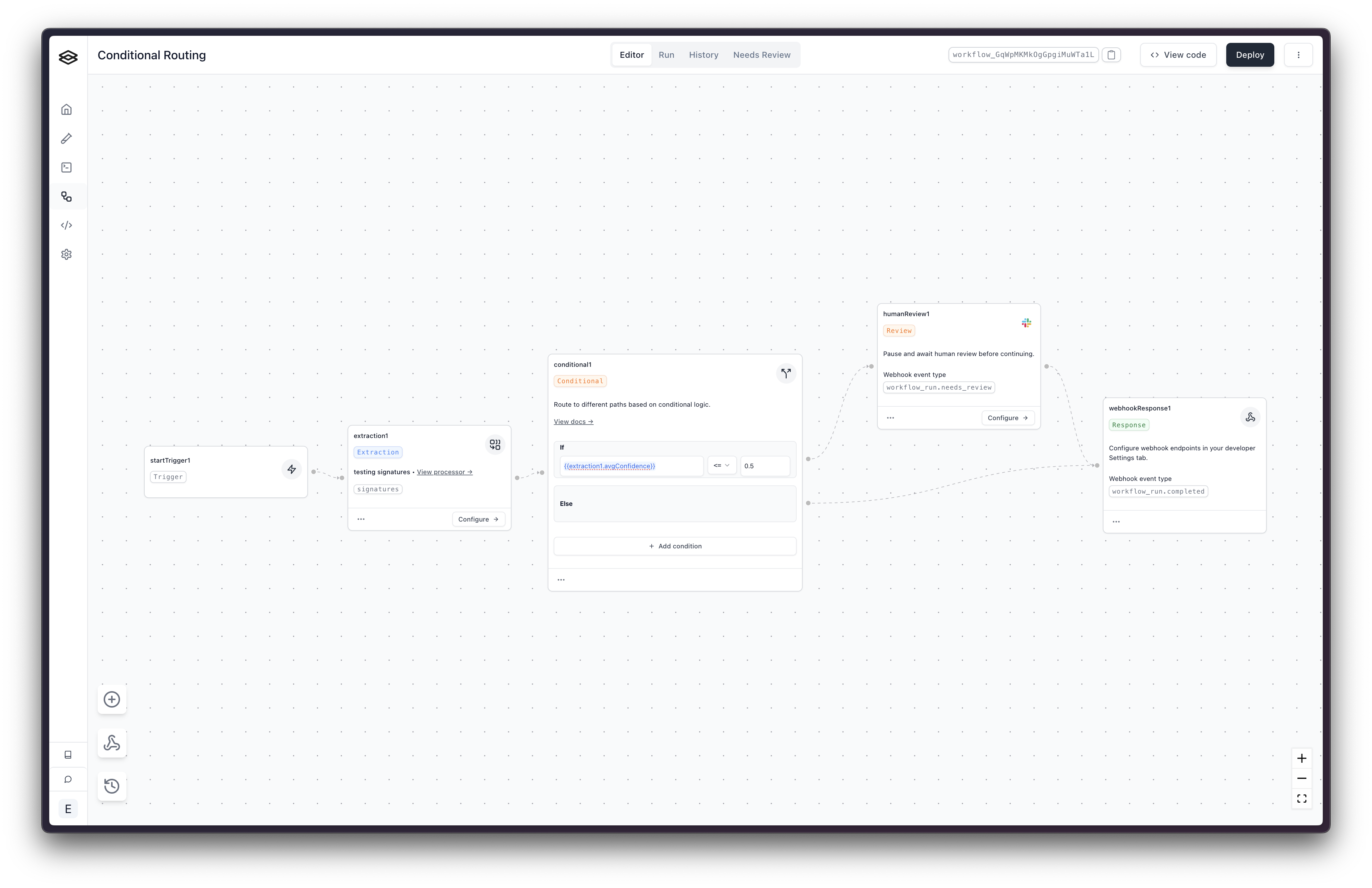
Specific Field Confidence Access:
{{extractionStepName.output.metadata.field_name.logprobsConfidence}} - Language model confidence for a specific field{{extractionStepName.output.metadata.field_name.ocrConfidence}} - OCR confidence for a specific fieldArray and nested object confidence access (e.g., line_items[0].description) is not currently supported in conditional steps.
Example Conditional Logic:
Confidence scores are provided for arrays at multiple levels:
arrayName[index] notationarrayName[index].propertyName notationTo access confidence scores programmatically: