Stay up to date on what’s shipping in the Extend platform.
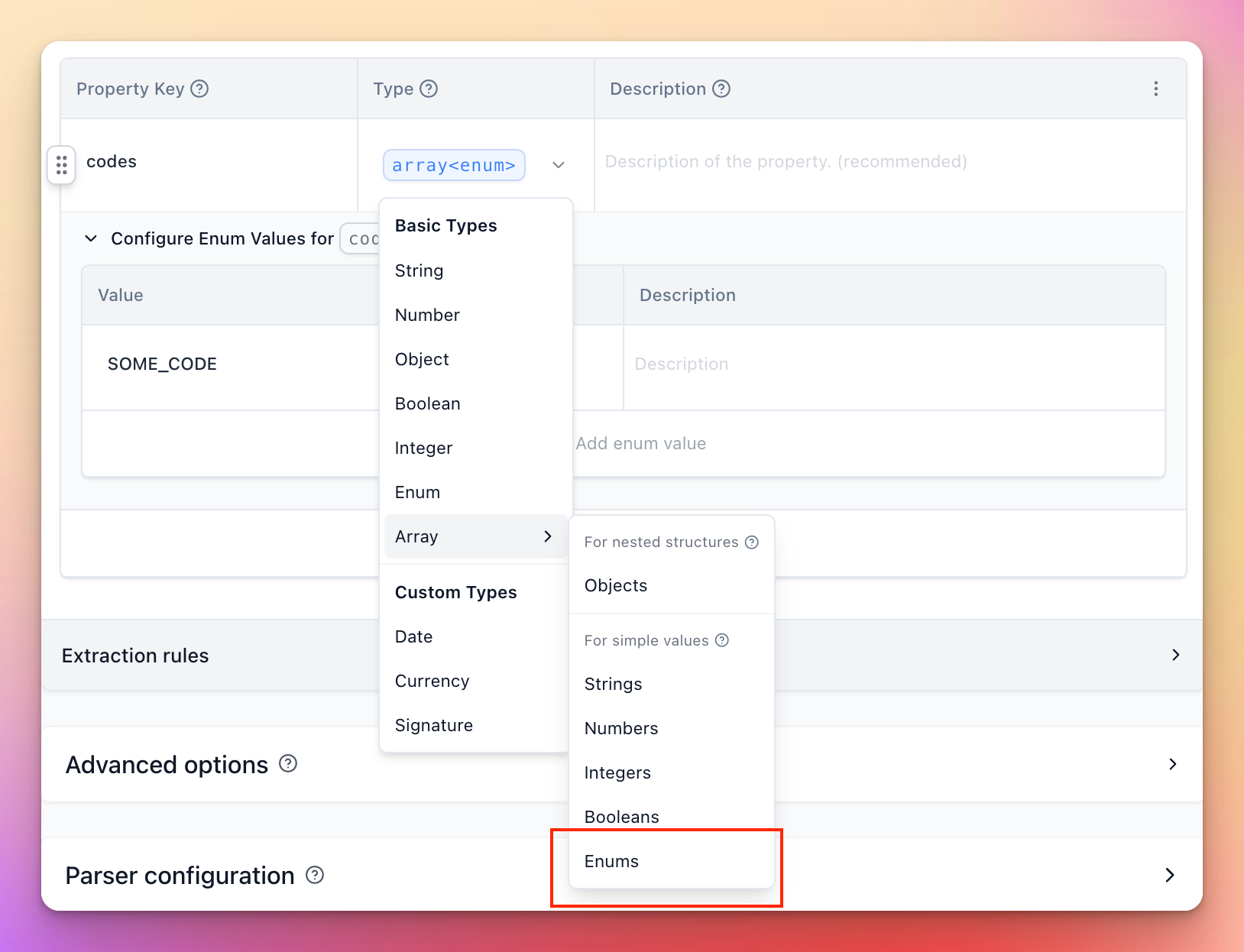
Array(Enum) support in extraction schemas
Array(Enum) support in extraction schemas
A long-standing legacy limitation is gone: with base extraction version 4.6.1, you can now use Array(Enum) as a field type to extract arrays of enumerated values directly in your schemas.
New API version (2026-02-09)
New API version (2026-02-09)
A major new API version brings dedicated typed endpoints for each processor (extractors, classifiers, splitters), synchronous processing, inline config runs, SDK polling and webhook helpers, Zod schema support, and simplified response shapes.
The unified /processors and /processor_runs endpoints have been split into dedicated, fully-typed endpoints — no more checking type fields or casting outputs.
See the full migration guide for everything that’s new.
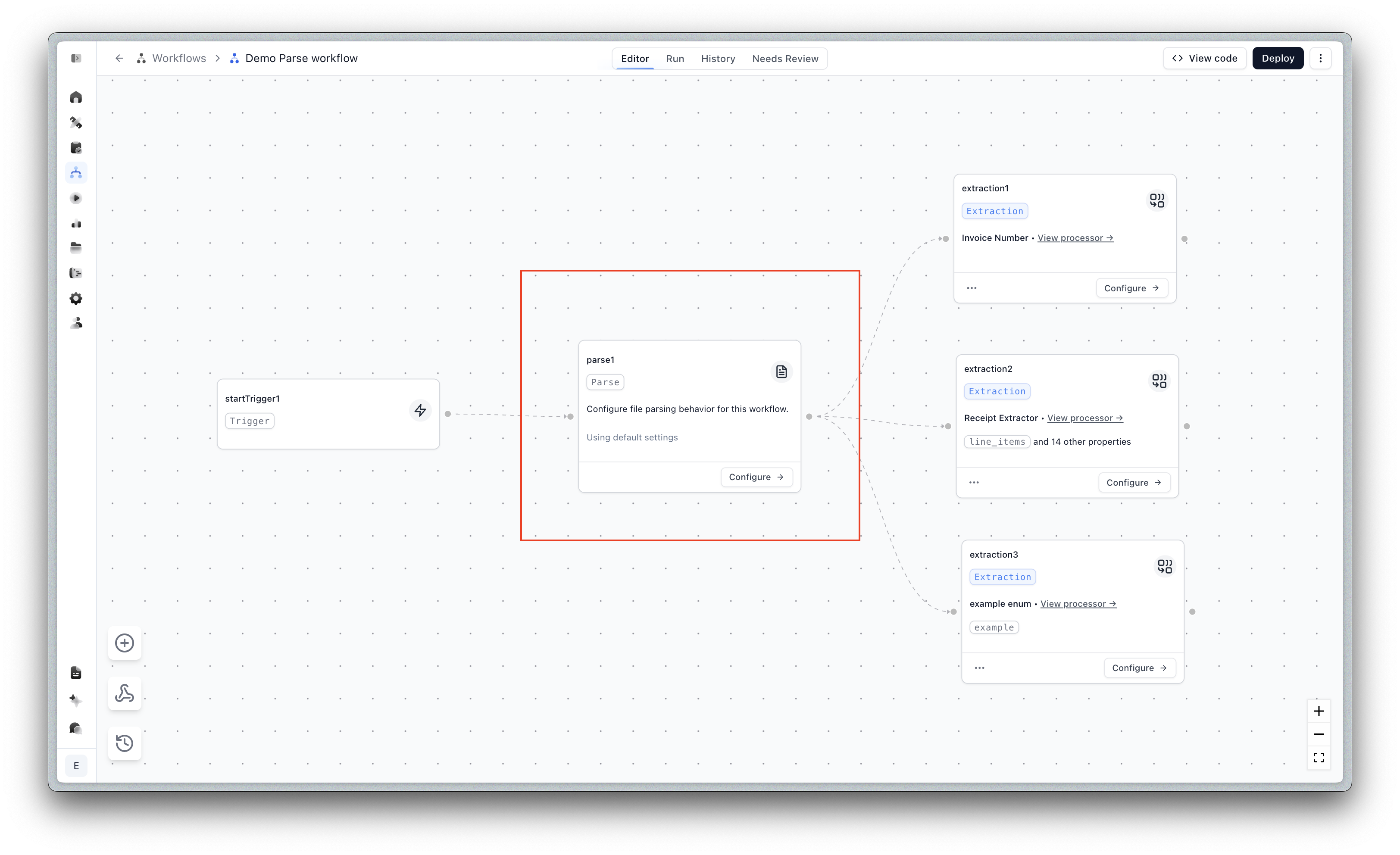
Parse step in Workflows
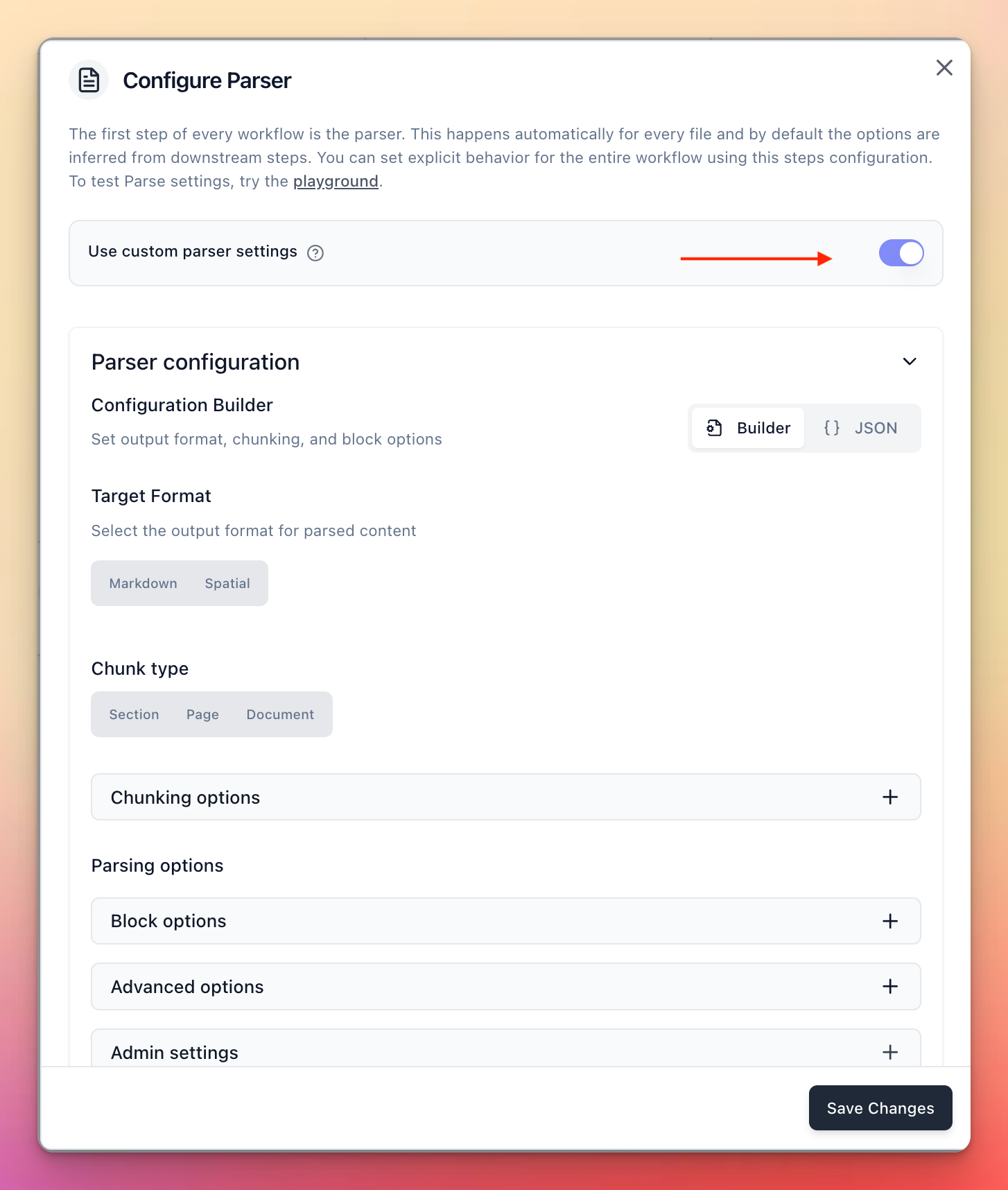
You can now add a Parse step directly in Workflows for more flexible document processing pipelines. Previously, parsing happened automatically in the root node and options were inferred from downstream steps. Now you can configure the step with your own parse config — and in the new API version, get parse results back without a second API call.
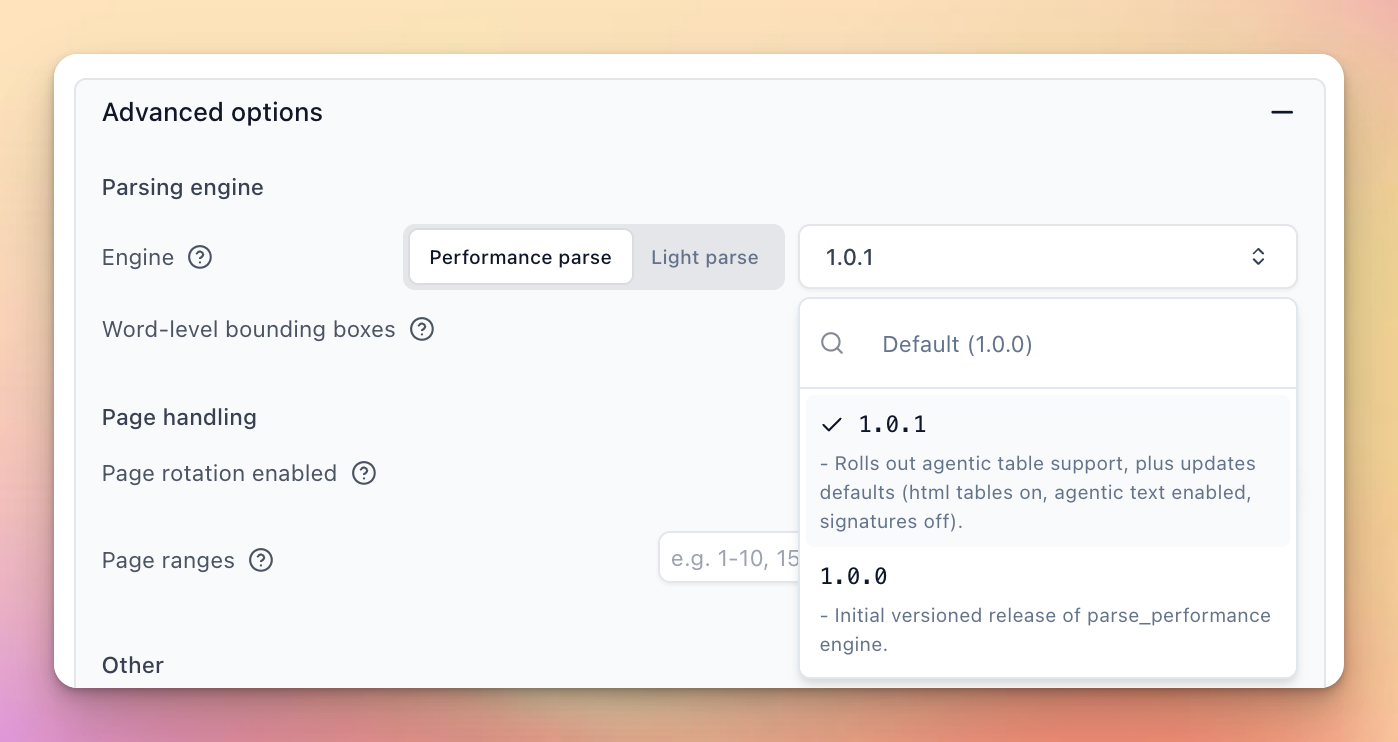
New parse versions with agentic controls
Two new parse versions are out:
- Performance 1.0.1 — adds agentic table support and
advancedLLM-enhanced Excel parsing, and updates defaults (HTML tables on, agentic text enabled, signatures off). - Light 0.2.0-beta — brings complex layout element support to the Light Parser at a fraction of the cost and latency of Performance.
You can now configure parse engine and version for all parse calls (not just within an extraction pipeline), and toggle agentic processing at the block-type level — for example, only enable it for tables.
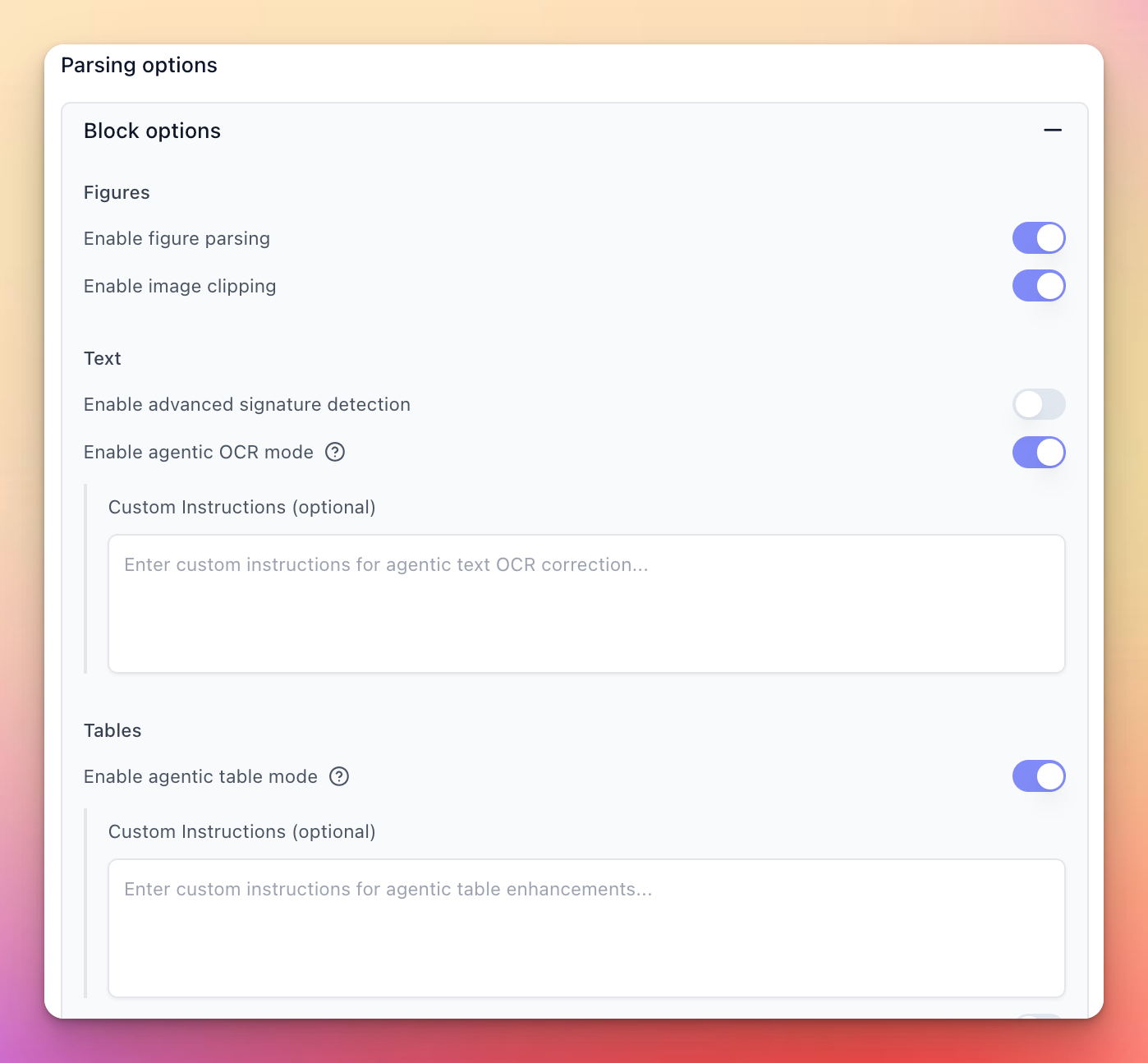
Try them out in the Parse Playground.