Composer
Composer is an AI assistant that helps you improve your configurations in Extend: extraction schemas, splitters, etc.
The Composer agent is currently in beta and is not available to all users. If you would like to be added to the beta, please contact us at support@extend.ai or via Slack if you have a shared channel with us.
Overview
Right now, Composer is only available for extraction schemas and can be run as a background agent to optimize your schema based on what it learns from your verified evaluation sets.
Key benefits:
- Automated improvement: Let AI analyze and optimize your extraction rules
- Data-driven optimization: Uses real evaluation data to guide improvements
- Measurable results: See exact accuracy improvements for each field and what changes were made before applying updates
- Time savings: Reduce hours of manual configuration tuning to minutes
How It Works
The Composer agent has access to the following tools to optimize your schema:
- Analyze: Examines your current extraction configuration and evaluates it against your chosen evaluation set(s)
- Read: Can view individual files and outputs in the evaluation set to understand what’s going on
- Generate: Creates multiple candidate improvements for field descriptions and extraction rules
- Evaluate: Tests each candidate configuration against the evaluation set
The background agent runs these processes in a loop (limited via “Max generation runs”) to find the best possible improvements.
Prerequisites
Before running the Composer, ensure you have:
The quality of optimization results directly depends on the quality of your evaluation sets. Poor or unrepresentative ground truth data will lead to suboptimal or incorrect optimizations.
1. High-Quality Evaluation Sets
Your evaluation sets must have:
- Representative samples: Include diverse examples that reflect real-world documents
- Accurate ground truth: Manually verified correct values for all fields
- Sufficient coverage: At least 20-30+ documents for reliable optimization
- Recent data: Evaluation sets should reflect current document formats and content
2. Stable Schema Structure
Before optimization:
- Finalize your schema structure (field names, types, nesting)
- Use clear, unambiguous field names that accurately describe the task
- Avoid vague or generic field names like “value1” or “data”
3. Clear Extraction Rules
Ensure your initial extraction rules:
- Clearly define what should be extracted for each field
- Include any specific formatting or validation requirements
- Specify how to handle edge cases or missing data
Configuring Composer
Before using Composer, Publish your processor to create a new version. This will allow you to revert changes if apply the updates, but the optimizations don’t perform as expected in production.
To run the background agent:
- Navigate to your processor’s Performance tab
- Click the Optimize button
- Configure the optimization parameters
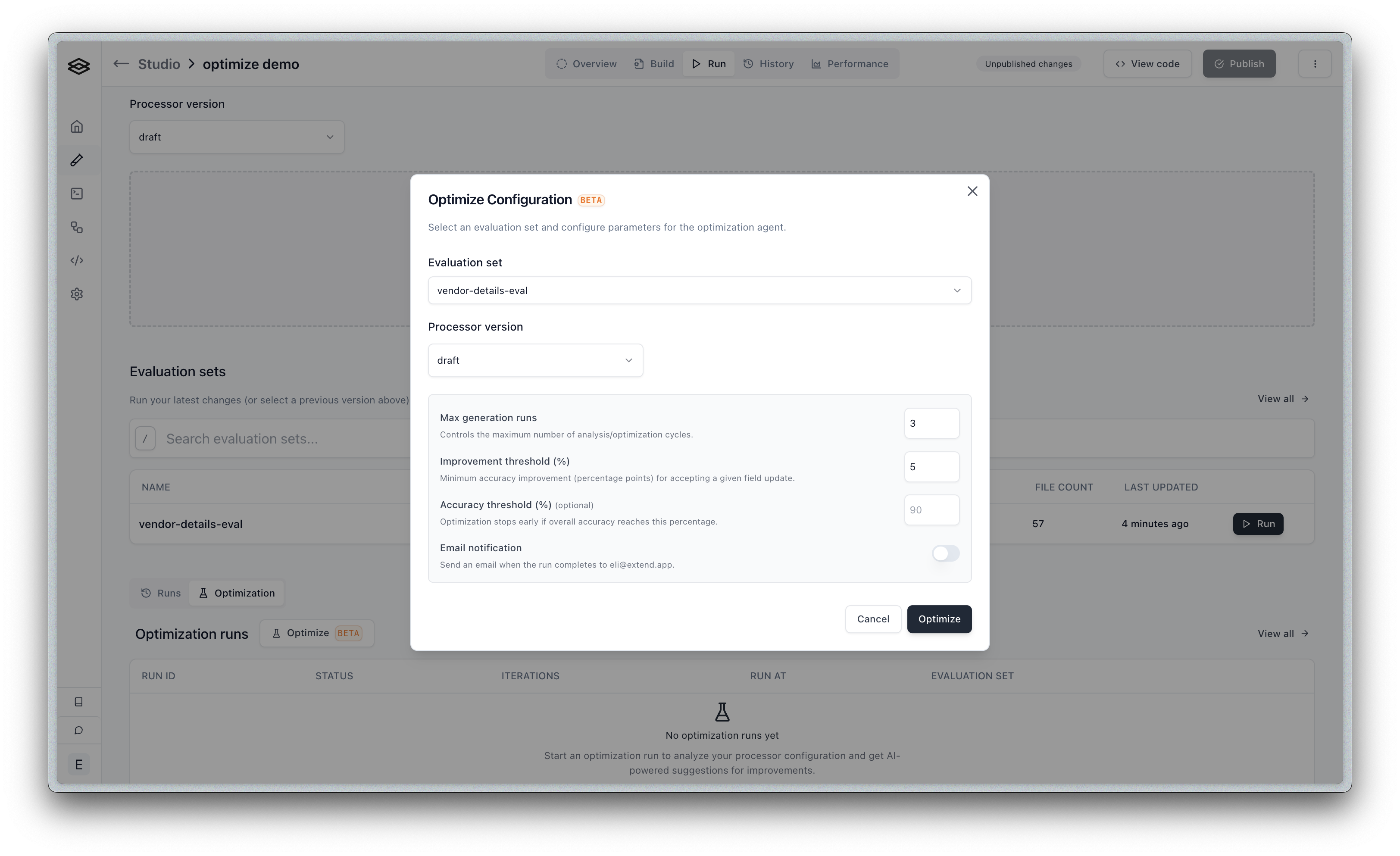
Evaluation Set
Select the evaluation set to use for optimization. The agent will test improvements against this set to measure accuracy gains.
Choose an evaluation set that best represents your typical documents. Using a non-representative set may lead to optimizations that work well for the test data but poorly in production.
Processor Version
Select which version of your processor to optimize. Typically, you’ll optimize your draft version before publishing.
Max Generation Runs
Controls how many generation runs the agent will perform (default: 3). The higher the number, the longer it will take to complete, and the more credits it will cost, however allowing for more generations will almost always lead to better results.
Improvement Threshold (%)
The minimum accuracy improvement required to consider a change worthwhile (default: 5%).
- Changes below this threshold won’t be suggested
- Set higher to reduce noise and only show changes that are guaranteed to be impactful
- Set lower to see all potential improvements
Email Notification
Enable to receive an email when the optimization run completes. Recommended for longer runs.
Running the Optimization
- After configuring parameters, click Optimize
- The optimization will run in the background
- Monitor progress in the optimization runs table
- Once complete, review the proposed changes
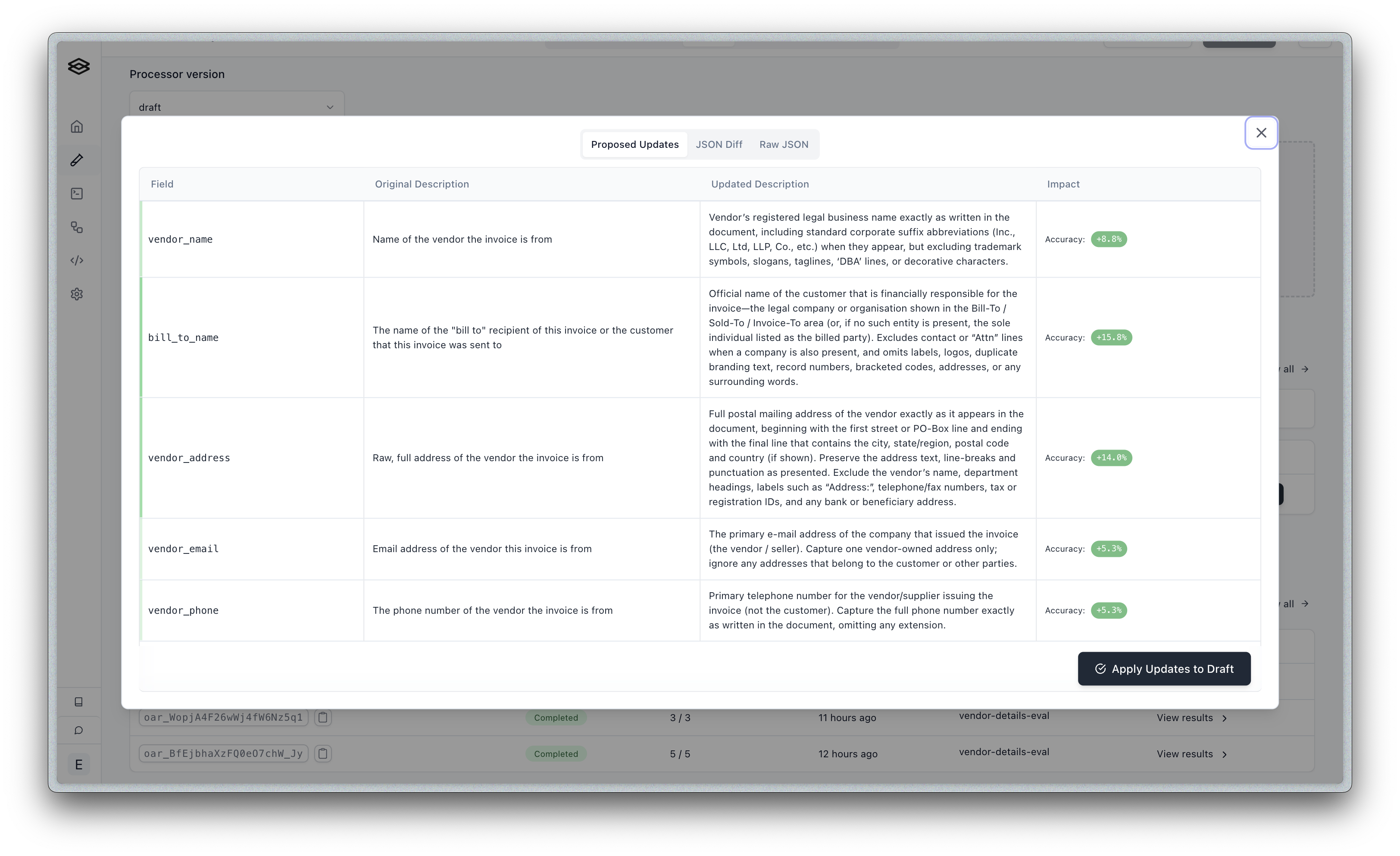
Reviewing Results
When optimization completes, you’ll see a detailed view of proposed changes:
Understanding the Results
The results view shows:
- Field-by-field improvements: Each optimized field with its accuracy gain
- Original vs. Updated descriptions: Side-by-side comparison of changes
- Impact metrics: Percentage accuracy improvement for each field
- JSON diff view: Technical view of exact configuration changes
Interpreting Accuracy Improvements
- Green percentages (e.g., +17.5%): Significant improvements worth applying
- Higher improvements (>20%): Major gains, often from clarifying ambiguous descriptions
- Modest improvements (5-10%): Incremental gains that add up across many fields
Applying Changes
After reviewing the proposed optimizations:
- Review each change carefully to ensure it aligns with your extraction requirements
- Check the updated descriptions for accuracy and clarity
- Click Apply Updates to Draft to update your configuration
- Test the updated configuration with additional documents
- Monitor performance after deploying to production
You can always revert changes by using the version history if the optimizations don’t perform as expected in production.
Limitations
Current limitations of the Composer agent:
Technical Limitations
- Schema structure: Cannot modify field types or schema structure. Does not currently handle deeply nested (> 2 levels of nesting) fields well.
- Advanced options: Cannot yet modify advanced options in your processor (e.g. chunking options, etc)
Performance Considerations
- Large evaluation sets: Optimization time increases with evaluation set size
- Complex schemas: Deeply nested schemas may take longer to optimize
- Iteration limits: Improvements plateau after 5-7 generation runs
Troubleshooting
Common Issues
Optimization shows no improvements
- Check evaluation set quality and size
- Ensure field names clearly indicate expected content
- Verify current descriptions aren’t already optimal
- It’s possible the bottlenecks to increasing accuracy are not things that can be improved by the Composer agent. For instance:
- If it’s a limitation of parsing the document (for instance illegible text, etc)
- If the current chunking strategy is not enabling the extraction process to work properly
Accuracy decreases after optimization
- Evaluation set may not be representative
- Ground truth data may contain errors or inconsistencies that cause the agent to make incorrect assumptions
- Consider using a different evaluation set
Optimization takes too long
- Reduce max generation runs
- Use a smaller evaluation set for initial optimization
Applied changes don’t improve production accuracy
- Production documents may differ from evaluation set
- Add more diverse documents to evaluation set
- Re-run Composer with updated data