Configuring an Extractor (Legacy)
Configuring Fields (Legacy)
This section is relevant only if you are using the older “Fields Array” config type. For new processors, we strongly recommend using the JSON Schema config type described in the “Configuring Properties” section above. If you aren’t sure, please see the Migrating to JSON Schema documentation.
To configure a field in the legacy system, add a semantically accurate field name and write a description that explains how to identify and extract that field from the document.
You must also configure the proper field type:
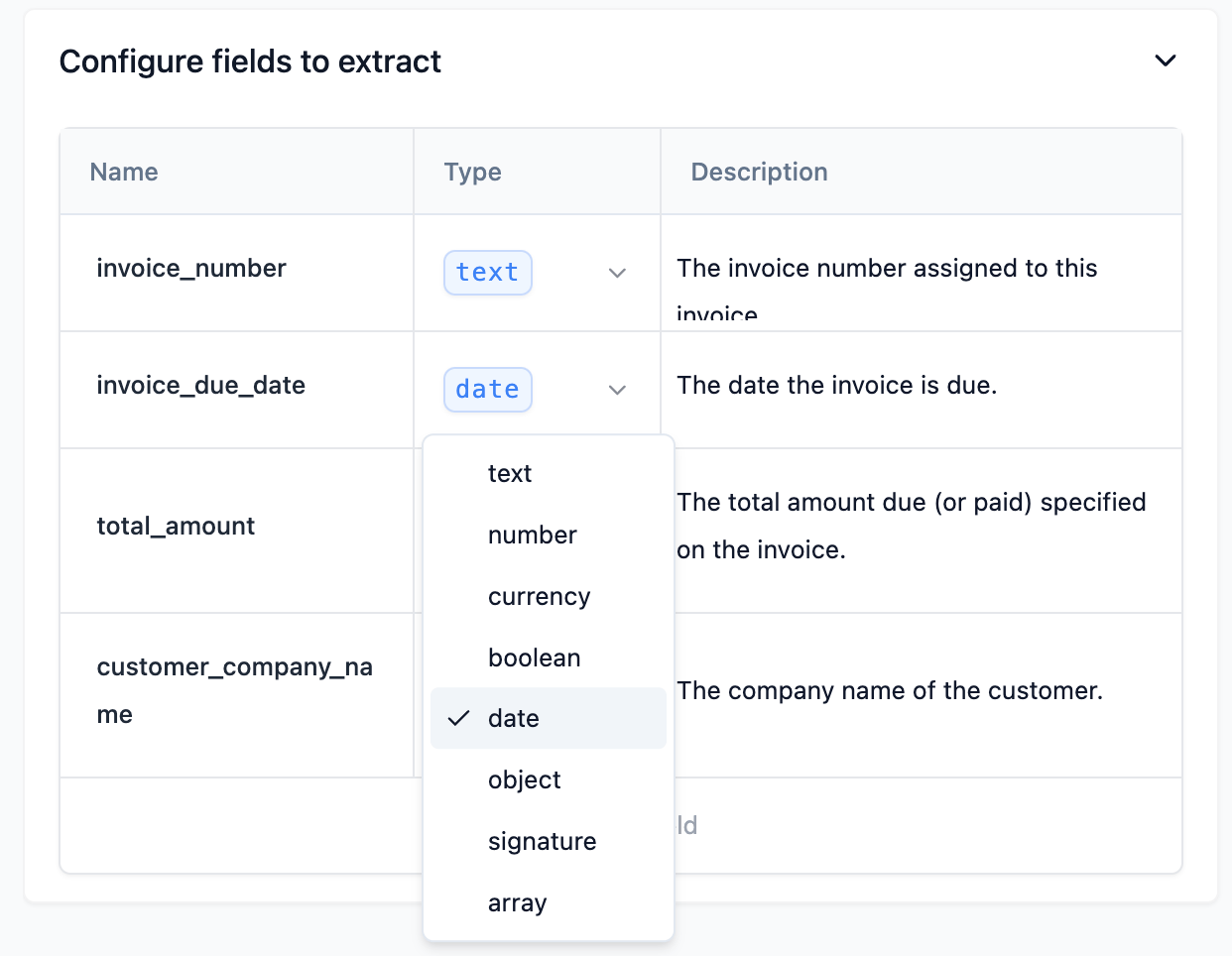
Text
Use the text data type when you want to extract a string of text from a document. For example, if you want to extract the name of a person from a document, you would use the text data type.
Number
Use the number data type when you want to extract a number from a document. For example, if you want to extract the age of a person from a document, you would use the number data type.
Currency
Use the currency data type when you want to extract a currency value from a document. For example, if you want to extract the price of a product from a document, you would use the currency data type.
Boolean
Use the boolean data type when you want to extract a boolean value from a document. For example, if you want to extract whether a product is in stock from a document, you would use the boolean data type.
Date
Use the date data type when you want to extract a date from a document. For example, if you want to extract the date of birth of a person from a document, you would use the date data type.
Signature
Use the signature data type when you want to extract a signature from a document. For example, if you want to extract the signature of a person from a document, you would use the signature data type. Signature fields will automatically extract all relevant details of a document’s signature block:
- is_signed
- printed_name
- signatory_title
- signature_date
Object
Use the object data type when you want to extract a set of related fields from a document. For example, if you want to extract the address, name, and birth date of a person from a document you would use the object data type.
Array
Use the array data type when you want to extract a list of related fields from a document. For example, if you want to extract a list of products that each have a name, price, and quantity from a document you would use the array data type.
Configuration table
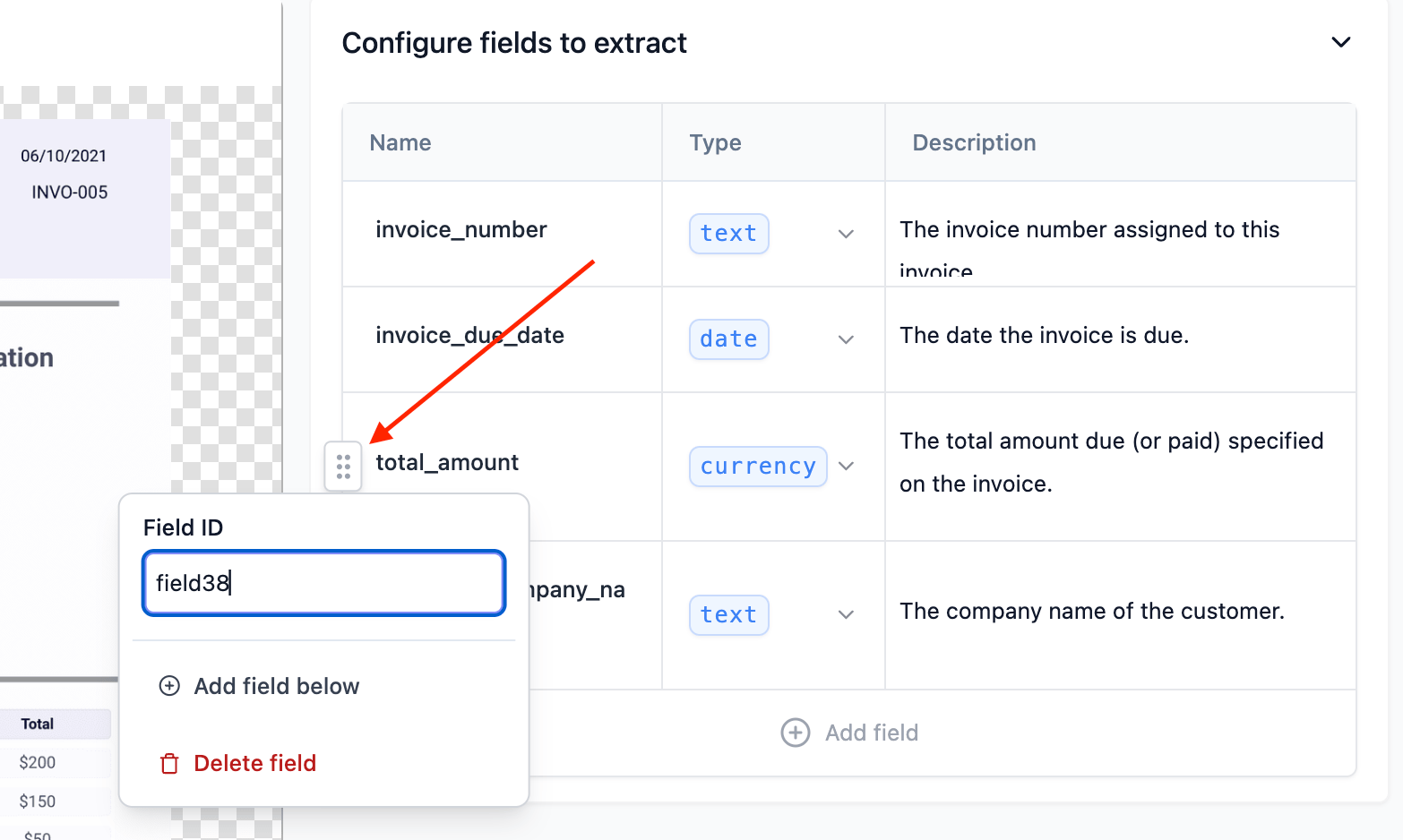
The field config table also will allow you to select the drag button to move the field up or down. Performance is best when related fields in the document are positioned in related order in the configuration table.
The below documentation about field IDs is relevant for the legacy Fields
Array config type. This is not relevant for the JSON Schema config type.
You can also set a field ID which is a unique identifier for the field to use in your downstream system, so that you can make changes to the semantic field name without
updating your downstream system.
Configuring Custom Settings
In addition to the fields, you can also configure custom settings for each field. These settings allow you to further customize the extraction process to better suit your specific needs. However, please note that these settings are experimental and may not work as expected in all cases.
Before using these settings, we recommend consulting with the Extend team to understand their potential impact on the extraction process.