Classification Overview
Classification assigns a document to exactly one of the categories you define and returns the match as structured JSON. You describe the possible document types with classifications, and Extend returns the matched type, a confidence score, and reasoning behind the decision. Use it to route incoming documents (invoices vs. bills of lading vs. purchase orders), gate downstream processing, or branch a workflow based on document type.
Classify runs Parse under the hood, parsing the file first if it hasn’t been parsed already and reusing the existing parsed output if it has.
Quick start
We’ll classify a freight invoice into one of several logistics document types. For this quick start we’ve uploaded the file here.
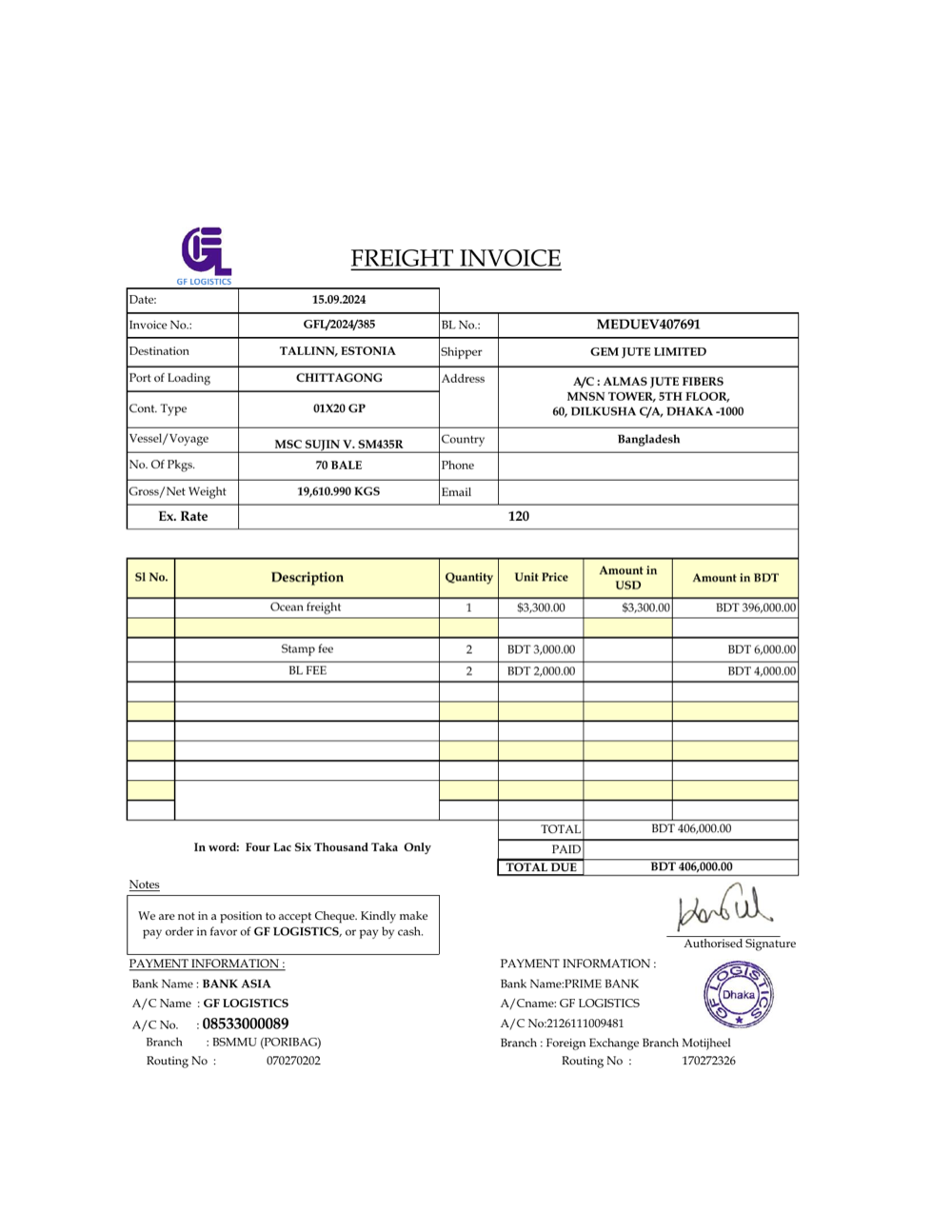
Grab a key from the Developers page and store it as the EXTEND_API_KEY environment variable. If you’re using an SDK, see the installation instructions.
The /classify endpoint takes a file and a config with the classifications you want to choose between.
Python
TypeScript
Java
Go
cURL
Want to classify your own document? Upload it first, then pass the returned file id instead of a url (reusing the same config).
Python
TypeScript
Java
Go
cURL
Example response
After you run the code snippet above, you’ll see a response like this. Extend parses the document, picks the best-matching category, and returns an output with the matched classification, a confidence score, and insights explaining the decision.
Key fields
For full request/response details, see the Create Classify Run API reference.
Use the output
Branch your logic on the returned id, and use confidence to decide when to route a document to manual review. Match on id rather than type: the id is a stable identifier you control, while type and description are part of the prompt that steers the classification decision and may change as you tune accuracy.
Python
TypeScript
Java
Go
For the full output shape and shared types, see Response Format.
Sync vs async
The example above calls the synchronous /classify endpoint. We also have an asynchronous /classify_runs endpoint that should be used for large files and high volume use cases.
See Async Processing for the full comparison, polling options, and webhook setup.
Save it as a processor
The quick start runs with an inline config, which is perfect for getting started. To reuse a configuration across runs — and to version it, measure its accuracy, and optimize it — save it as a classifier, a kind of processor. Processors are the saved entities you iterate on in the dashboard, run evaluation sets against, and improve with Composer.
Configuration
The quick start sends just file and config.classifications. To control how classification runs, pass more options inside config. Here are the most commonly used ones; for the full reference, see Configuration.
Classifications
The classifications array is the heart of every classifier — the set of categories the model chooses from. Each entry needs a unique id, a type returned in the output, and a description (your biggest lever on accuracy). At least one classification must have the type "other" as a catch-all.
Base processor
Choose the processor based on your accuracy and latency needs.
Classification rules
Steer the model with plain-language rules — useful for disambiguating categories that look similar.
Parse config
Because Classify runs Parse under the hood, you can tune how the document is parsed before classification with parseConfig.
For every option, including advanced options like context, multimodal processing, and memory, see the Configuration reference.